국가대표 AI에 대한 이모저모
국가대표 AI 선발전, "챗GPT나 제미나이 등 글로벌 AI 모델의 95% 이상 성능을 확보하는 한국형 독자 AI 모델"라고 나무위키에는 적혀있는데 뭐 대충 비슷한 뉘앙스로 이해하면 되겠다. 원래 나무위키 출처 같은거 가져오는 편 아닌데 어차피 진짜 공고를 봐도 목표가 별로 well-defined 되어 있을 것 같진 않아서...
2027년 목표로 5,300억원 규모로 GPU, 데이터, 인력 등을 지원한다고 한다. 즉 정부 입장에서는 굉장히 "크게 투자하는" 프로젝트인 셈이다. 그래서, 5개의 컨소시움을 경쟁 붙이고 하나를 뽑는 구도로 진행중이다.
근데 굉장히 골 때리는 일들이 많다.
2026년 1월 1일 "코사인 유사도" 사태
발단은 사이오닉 AI의 CEO 고석현이 링크드인에 "국민 세금이 투입된 프로젝트에서 중국 모델을 복사하여 미세 조정한 결과물로 추정되는 모델이 제출된 것은 상당히 큰 유감입니다." 라는... 굉장히 도전적인 문구를 게시하면서이다. 독파모 컨소시움 중 하나인 업스테이지 측의 새로운 solar 모델이, 분명 "entirely from scratch"를 내세웠는데, glm의 파인튜닝 버전이란다.
자, 앞부분만 읽고 나갈지도 모르는 독자를 위한 Disclaimer. 이 주장은 근거부터 제대로 도출되지 않았으며 모든 주장과 근거가 인간의 검토 없이 모두 AI로 생성된 주장이다.

그러면서는 solar-vs-glm이라는 github repository의 링크만을 댓글에 딱 올려뒀다.
와우. 새해 첫날 나는 저 정도의 강력한 스탠스로 폭로글을 올린다니, 대단한데? 라고 생각하며 내용물을 읽어봤다. 뭐 대충 보니 Claude든 Codex든 AI agent로 만든 리드미와 파일들이 보이긴 하는데 당연히, 이정도 주장을 했으니, 인간이 확실하게 검수를 했겠지? 라는 생각으로 몇군데 퍼다날랐다.
근데 몇시간도 지나지 않아 반응들이 이상하다. 조경현 교수님의 글, 고현웅님의 실험 리포트 등 신뢰도가 높은 인물들에게서 "아닌 것 같다"는 주장이 너무 빠른 시간 안에 들려온다. 시간이 어느정도 지난 다음에 이런 소식이 들려온다면 모를까... 처음 폭로(?)가 올라오고 몇시간도 지나지 않아 이정도 반론이 올라오는 건, 당연히도 굉장히 좋지 않은 시그널이다.
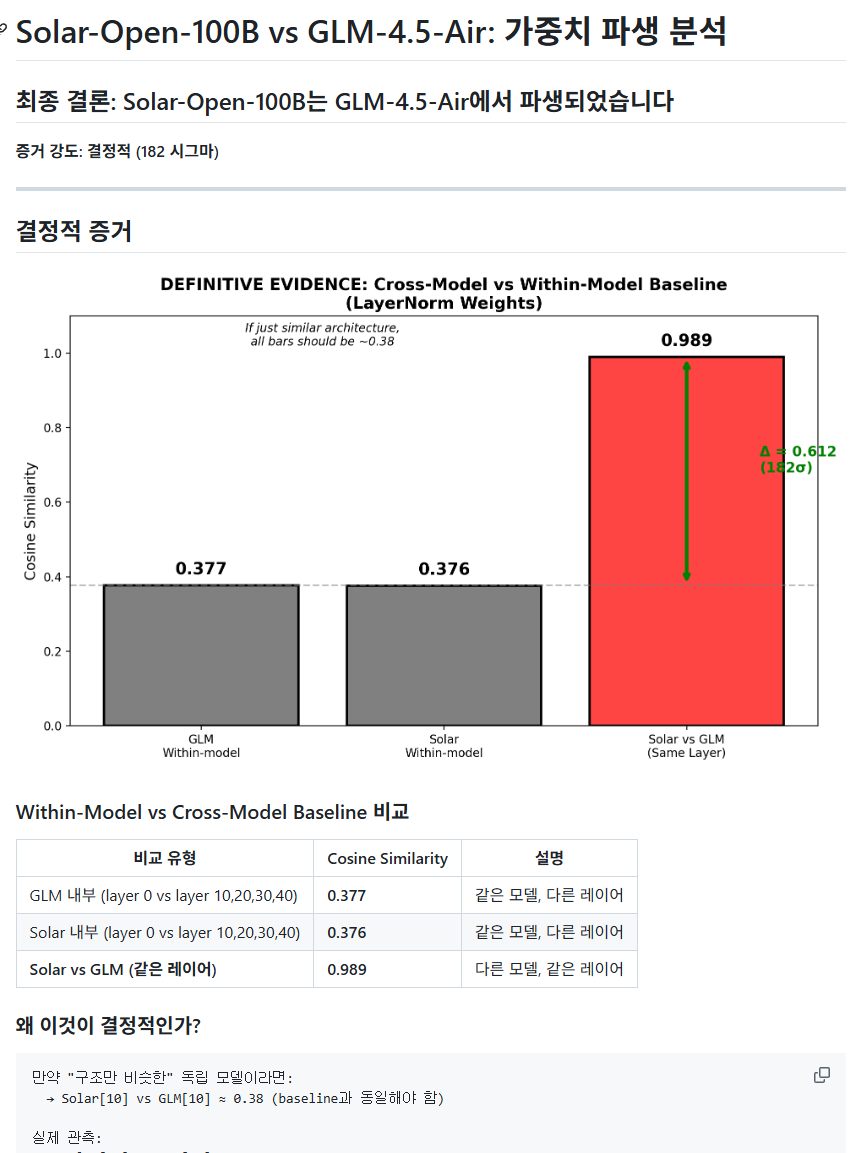
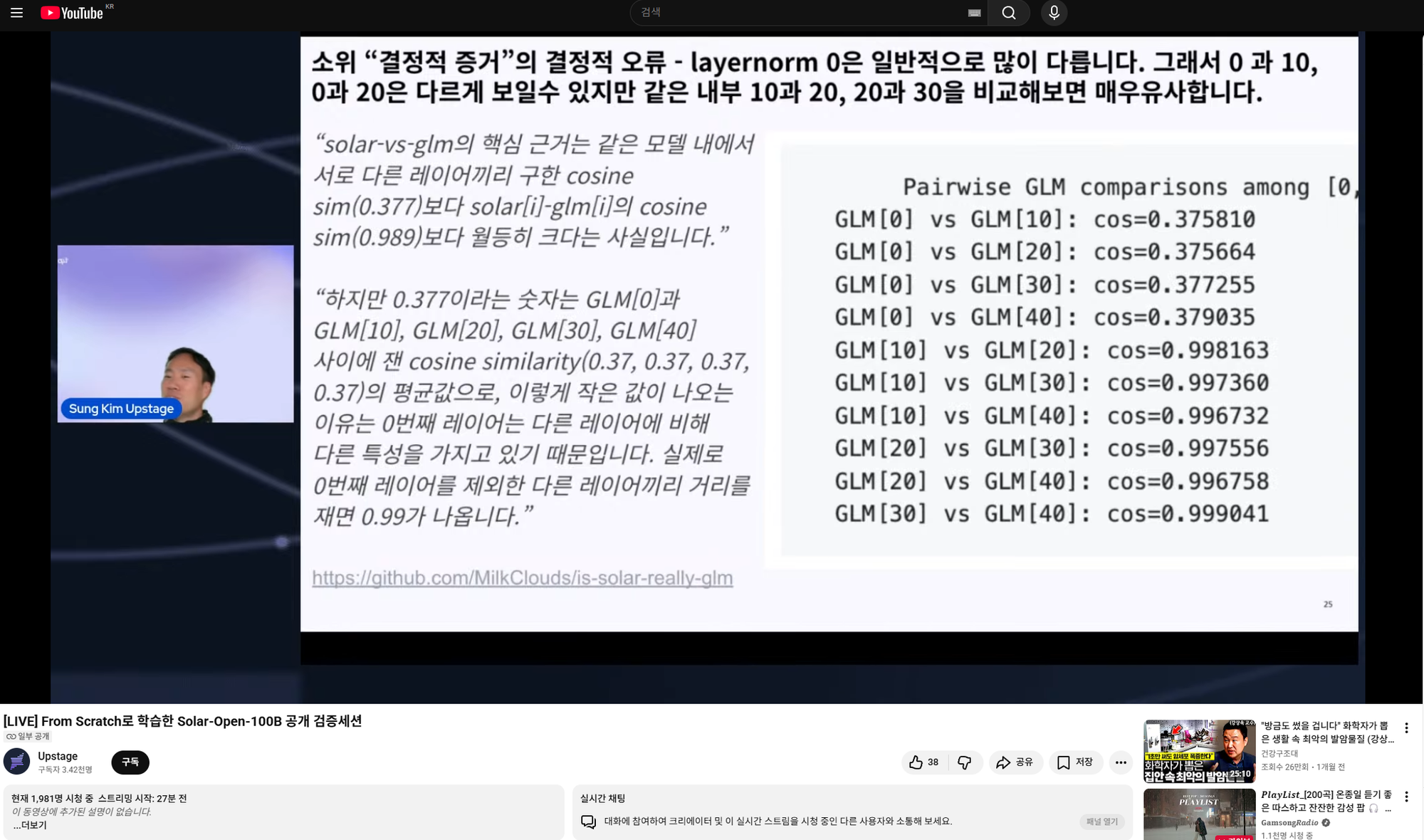
내용을 찬찬히 보면 분명 solar-vs-glm에서는 "같은 네트워크 내에서 다른 레이어끼리의 유사도"가 solar[i]-glm[i], 즉 "다른 네트워크끼리 같은 인덱스 레이어끼리 유사도보다 훨씬 높다"는 게 핵심 근거로 solar가 glm 기반이라 주장하는데, 조경현 교수님의 글에서는 그렇지 않단다. 이상하다.
새해 첫날 여유롭게 쉬고 싶었지만 너무 궁금했다. 그래서 집에서 맛있게 저녁을 먹고 딸기를 디저트로 먹으면서 코드를 clone뜨고 Codex에게 1번 물어봤다.
"여기서 같은 모델에서 서로 다른 레이어끼리 cosine sim 0.37 나왔다는데 관련 코드 찾아줘 어떻게 구현한건지"
답변은 다음과 같았다.

대체... 이게 뭔소리일까.....? 라는 생각이 처음 훑어보면서 바로 들었다.
정상적인 ML 엔지니어라면 아니 대체 왜 텐서를 raw bytes로 가져오고 왜 강제로 디코딩하는건데?? 라는 의문부터 바로 들 수밖에 없다.
그래서 다음 질문.
이거 구현 제대로된 거 맞아? 왜 그런식으로 계산해?
답변은 다음과 같았다.

음.
Codex에게 질문 2번하고 바로 답이 나왔다. 코드 이상하단다.
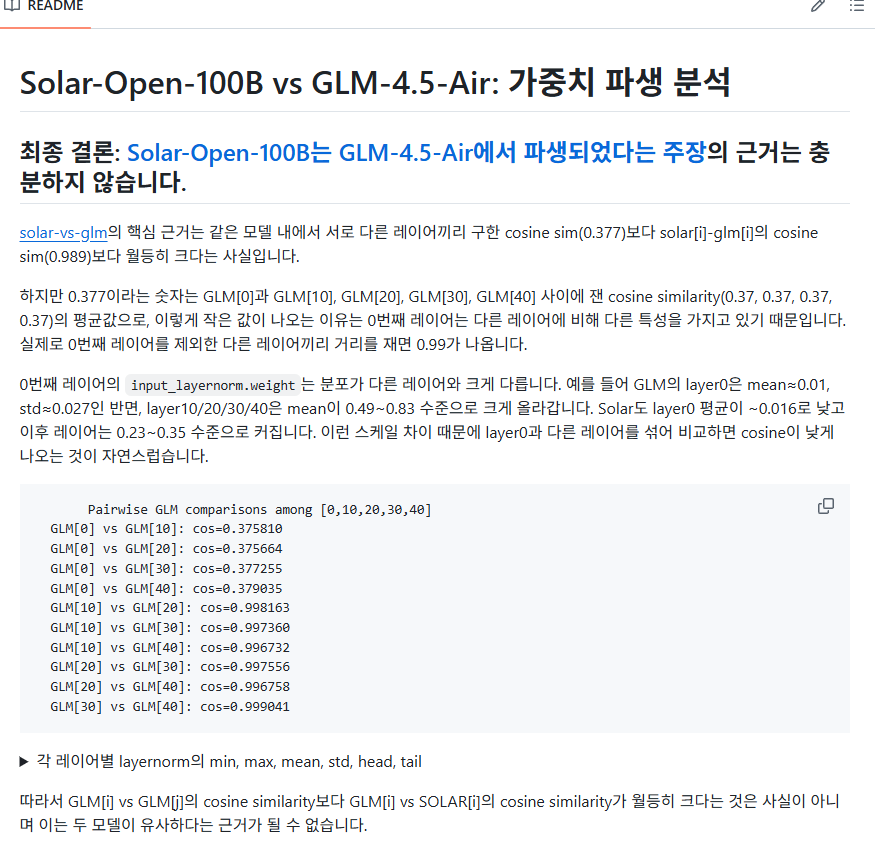
코사인 유사도가 1로 init되는 텐서에 적합하지 않은 메트릭인건 "두번째" 문제이다. 그보다 먼저, "첫번째" 문제는 solar-vs-glm 코드에서 GLM[0]과 GLM[10], GLM[20], GLM[30], GLM[40] 사이 거리를 재서 평균을 냈다는 것이다. layernorm은 뒤 레이어로 갈수록 1에 가깝게 증가한다는 것이 알려져 있기에 0번째와 다른 레이어의 텐서를 비교하는건 좀 말이 안된다. 랜덤으로 i,j combination을 추출하는게 말이 되지..
실제로 내가 재보니 0번째 레이어가 아닌 다른 레이어를 사용하기만 해도 결론은 "solar는 glm의 파생 모델이다"가 아니라 "solar는 glm의 파생 모델이 아니다"로 바뀌는 것을 확인했다. 너무나도 쉽게 결론이 바뀐다. 즉 근거로서 증거력이 매우 약하다는 말이다.
그리고 github에도 공개했다.
여기까지가, 1월 1일의 일이다.
2026년 1월 2일 업스테이지 방송
업스테이지에서는 바로 다음날 오프라인 및 온라인에서 해명(?) 방송을 진행했다.
나는 solar-vs-glm이 말도 안되는 소리라는 것을 직접 실험했기에 너무나도 잘 알고 있었기에 사이오닉에 대해 어떻게 대응할지, 사이오닉이 어떻게 대응할지 궁금해하며 방송을 대충 봤었다. 원래 오프라인 미팅만 할 줄 알았는데 방송까지 켜서 2000명이나 보더라.
오, 근데 내로라하는 연구자들이 낸 자료 대신 내 자료가 핵심 근거자료로 사용됐다. 아무래도 다른 자료들은 "코사인 유사도 대신 다른 지표를 쓰면 결과가 다르다" 혹은 "코사인 유사도를 더 재보니까 이상하더라" 정도라면, 내 자료는 "solar-vs-glm의 근거가 그 자체로 확실히 틀렸다"를 증명하기에 채택해가신 것으로 보인다. 2000명 보는 방송에 내 자료가 샤라웃되서 신났다.
사이오닉에 대한 대처는.. 그저 "사과를 요구함" 정도로 끝났다. 그 이상의 대처를 하더라도 전혀 이상하지 않다고 생각했으나 어느정도 무던하게 대응하셨다고 생각한다.
사이오닉의 CEO 고석현은 아래 글을 올렸다가..
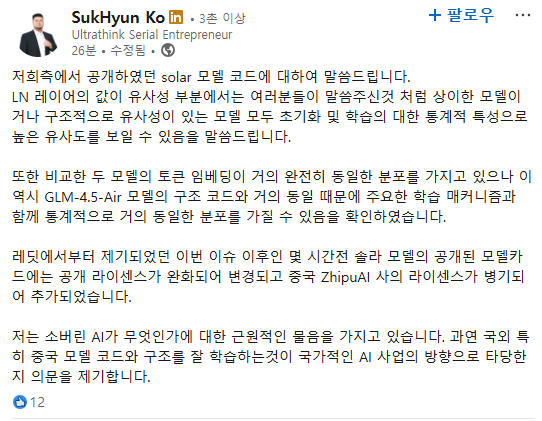
업스테이지의 해명(?) 방송 이후 이렇게 수정했다.
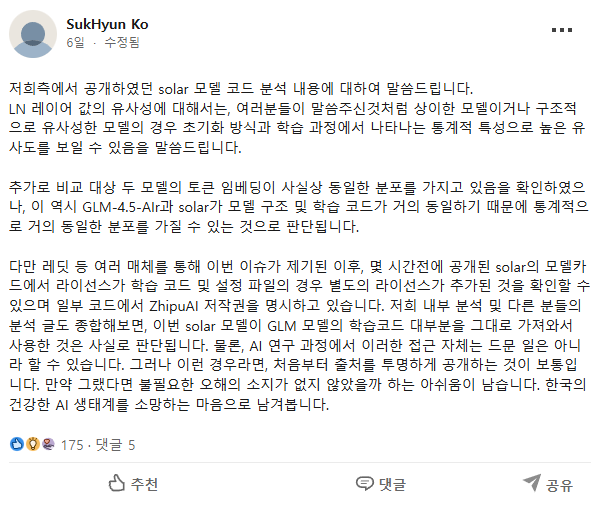
그의 의도 저편에 과연 정말로 우리나라 인공지능 업계와 생태계를 발전시키려는 선한 마음이 있었을까? 나는 잘 모르겠다.
2026년 1월 8일, 국가대표 AI에 중국산 '떡'…'눈과 귀' 빌려다 쓴 꼴? / SBS 8뉴스
이제는 네이버의 omnimodal 모델의 인코더/디코더가 중국산이란다.
대체, 어디까지 "독자의 힘으로" 해야 하는 걸까?
- 중국산 인코더를 쓰지 않는 것
- 인코더를 독자적으로 학습하기 위해 데이터가 필요한데 그 데이터를 필터링하는데에는 이미 중국산/미국산 인코더가 쓰였을 것이다. 그럼 데이터도 쓰지 말아야 하는건가? 그럼 데이터를 필터링하기 위해 필요한 인코더를 학습하기 위한 데이터를 필터링해야 하는가?
- 아니 생각해보니 애초에 데이터가 국산이 아니잖아? 그럼 국산 데이터만 써야되는건가? 근데 국산 데이터가 뭐지? 한국인이 만든것만 써야하나?
- 근데 생각해보니 딥러닝 프레임워크인 파이토치는 미국산이다. 쓰면 안되는건가?
- 근데 생각해보니 프로그래밍 언어인 파이썬은 미국산이다. (아마?) 쓰면 안되는건가?
- 근데 생각해보니 OS는 미국산이다. 쓰면 안되는건가?
- 근데 생각해보니 ISA도 미국산이다. 쓰면 안되는건가? 아니 cpu도 gpu도 다 국산은 아닌데...
사람들은 타임머신 타고 2016년에 돌아가서 4개월동안 시간 동안 2026년의 ChatGPT를 만들어내길 원하는걸까.
예전에 봤던 긱뉴스도 생각이 나고.
이전의 업스테이지 글도 누구의 말이 옳고 그른지 정말 명확한데도, 기사에서는 "그 주장이 확실히 틀렸다"라고 서술이 되지 않고 "99%만큼 일치하더라는 주장이 있었다"는 식으로 서술되는 것을 봤었다. 기자의 무지가 오해를 전파하고. 대중의 무지는 오해를 더더욱 전파하는 것이다.
권위 있는 지식인이 언론에 노출되며 의견을 드러내 여론을 휘어잡는 게 중요한걸까. 근데 그렇게 노출된 지식인이 정말로 지식인이 아닌 경우가 많다는 사실은 차치하고, 실제로 전문성이 있는 사람일지라도 의견 표출에 있어 전문성이 없는 정치인들에게 밀리는 경우도 많던데. 참, 씁쓸하다.
전부터 교육에 대한 생각이 있다. 빅테크에서 뛰어난 엔지니어/리서처로 일하는 방향도 있지만, 교수로서 더 교육에 비중을 두는 방법도 있다. 고민이 드는 시기이다.