Papers Reading Experimental quantum speed-up in reinforcement learning agents 이 논문에서는 quantum algorithm을 이용해 reinforcement learning을 speed-up하는 것을 실험적으로 보입니다.
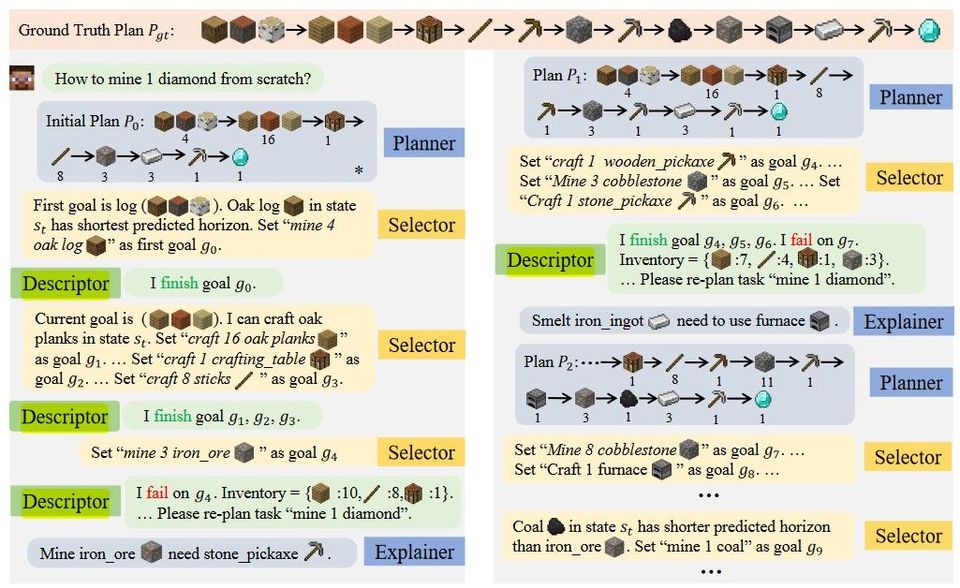
Papers Reading Describe, Explain, Plan and Select - Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents 이 글에서는 Large Language Model(LLM)에 별도의 fine-tuning을 하지 않고도
Papers Reading Neural Controlled Differential Equations for Irregular Time Series https://arxiv.org/abs/2005.08926 https://github.com/patrick-kidger/NeuralCDE
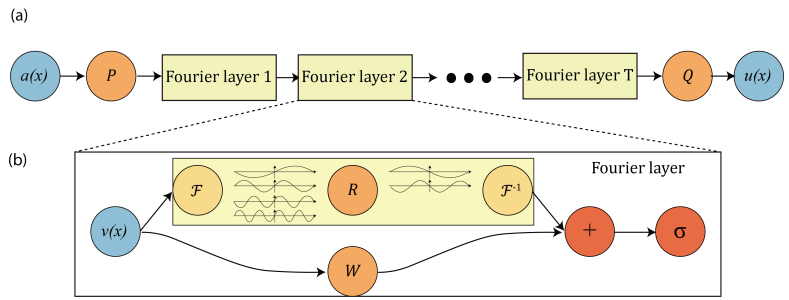
Papers Reading Fourier Neural Operator for Parametric Partial Differential Equations (ICLR 2021) 이 글은 논문의 모든 내용을 꼼꼼히 다루기보다는 핵심 내용만을 읽는데에 중점을 둡니다.
Papers Reading The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning https://blog.otoro.net/2022/10/01/collectiveintelligence/ 에서 처음 읽어서 https:
Papers Reading Growing 3D Artefacts and Functional Machines with Neural Cellular Automata 이번에 리뷰해볼 논문은 NCA(Neural Cellular Automata)에 대한 것으로, Yannic이 Sebastian
Papers Reading InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering https://arxiv.
Papers Reading Scalable Interpretability via Polynomials https://twitter.com/MetaAI/status/1536728499846688768?s=20&t=Sy6-wF8Jaxq1f6FSjrTBGg
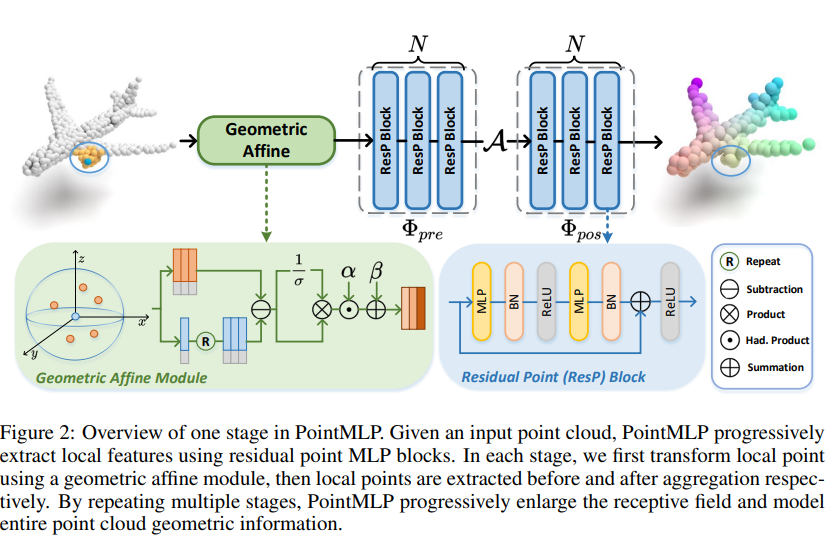
Papers Reading RETHINKING NETWORK DESIGN AND LOCAL GEOMETRY IN POINT CLOUD: A SIMPLE RESIDUAL MLP FRAMEWORK 오늘 조금 놀라운 논문과 실험 결과를 접해서 관련 논문을 리뷰하려고 한다. PointMLP라는
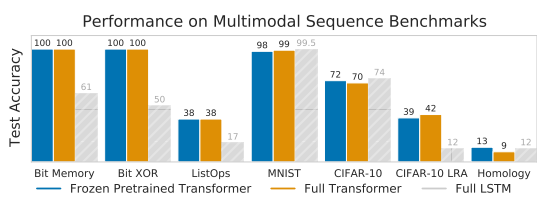
Papers Reading Pretrained Transformers as Universal Computation Engines 2021 3월 9일에 나온 Pretrained Transformers as Universal Computation Engines에 대한 간략한
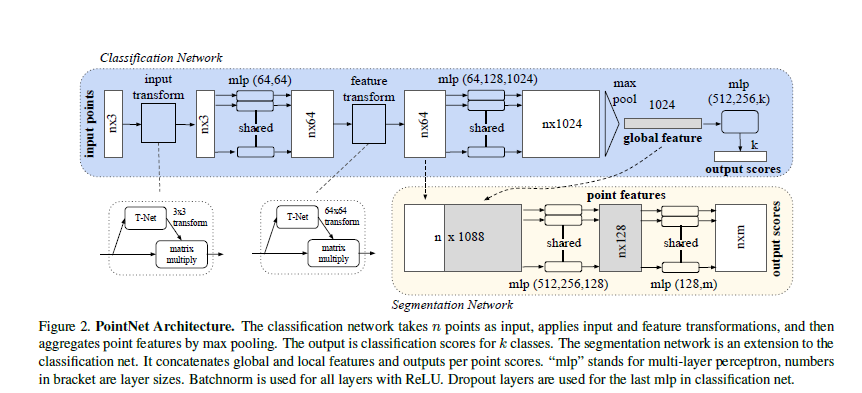
Papers Reading PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation 요약 내가 알기로 Point Cloud를 다루는 시초 격에 해당하는 논문으로, 이후 PointNet+
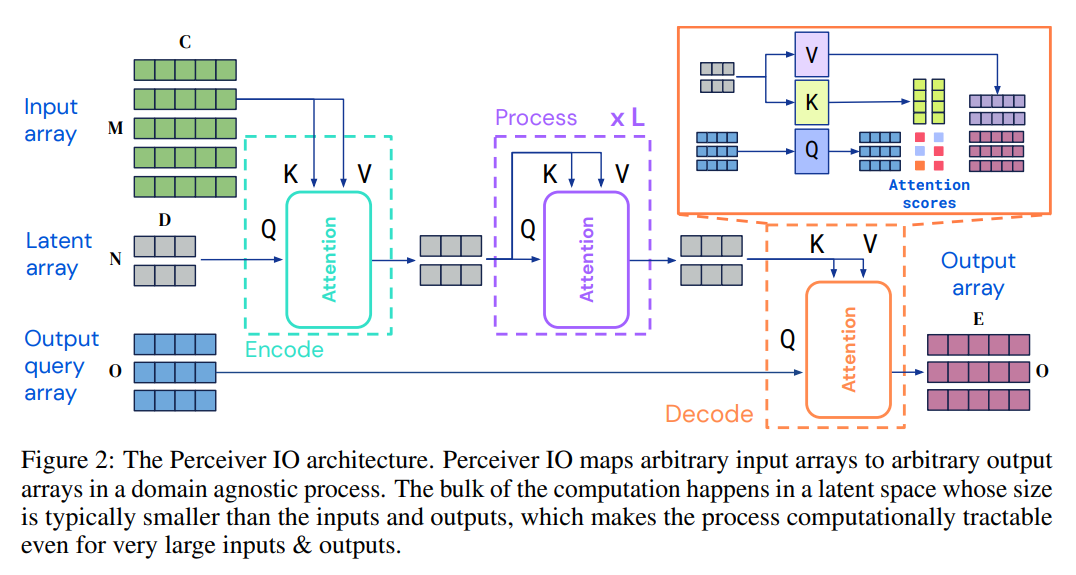
Papers Reading Perceiver IO: A General Architecture for Structured Inputs & Outputs 내가 이전에 올린 Perceiver [https://milkclouds.work/perceiver-general-perception-with-iterative-