InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering

InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering
https://arxiv.org/abs/2112.15399
https://cv.snu.ac.kr/research/InfoNeRF/
Shannon Entropy에 기반해 광선의 entropy를 minimze하고 여기에 KL divergence loss term을 더해 오직 4개의 이미지를 이용한 Few-shot NeRF에 좋은 성능을 낸다.
entropy minimization은 "가장 덜 noisy"한, 또는 "가장 덜 무질서한" 배치를 찾는 것으로 이해할 수 있고 KL divergence loss는 오버피팅을 방지하고 smooth한 배치를 찾는 것으로 이해할 수 있다. 아마도 (non-prior) few-shot NeRF가 노이즈가 꽤 많다는 것을 인지해 거기에서 착안한 게 아닐까 싶다.
3. Preliminaries: NeRF
다 좋은데, 하나 이상한 게 있다면
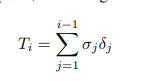
accumulated transmittance 수식이 이상하다. 이거 $e^{- \sum \sigma_i \delta_i}$ 아닌가?
근데 이런 기본적인 걸 논문에서 실수했을 것 같지는 않은데 뭘까?
4.2 Regularization by Ray Entropy Minimization
-
Ray Density: 정규화된 opacity(불투명성)

-
Ray Entropy: ray의 opacity에 대해 Shannon Entropy 수식 적용
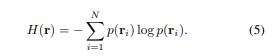
-
Disregarding non-hitting rays
만약 어떤 지점까지 ray가 지나온 경로의 total opacity가 일정 $\epsilon$ 이하이면 해당하는 점을 처리하지 않는다.
이런 처리가 혹시 정규화 가정을 깨지 않을까 생각을 해봤는데(ray opacity 분포의 합을 1로 만들고 일부를 무시하니 총합 1이 안됨), 정규화 가정이 깨지긴 하겠지만 $\epsilon$이 충분히 작다면 무시할 수 있을 것이라 생각이 들었다.
다만 하나 이상한 건 opacity는 곱, 또는 지수에 올라간 $\sigma_i \delta_i$를 sum하고 지수에 올려야 하는데 왜 opacity를 합하는지 약간 의문이 들긴 했다. 이것 또한 $\epsilon$과 비교한다는 그 목적을 따지면(거의 0에 수렴하는 것만 지우는 목적) 상관없겠지만.. 곱확률을 합확률로 논의 없이 바꾸는 듯한 찝찝함..
- Ray entropy loss
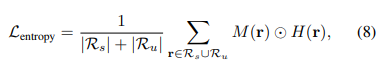
아무튼, $\mathcal{L}_{entropy}$를 위와 같이 정의한다. 특이하게도, unseen image의 ray에 대해서도 entropy loss를 고려해서 최소화한다. 이 쪽에 성능이 잘 나왔다고 한다.
4.3 Regularization by Information Gain Reduction
이제 지나치게 overfitting되는 이슈가 있어 '약간 벗어난' ray와 원래 ray의 KL divergence를 최소화시키도록 한다. 이렇게 하면 일반화된 분포가 형성되고 overfitting이 해소된다고 하는 듯하다.
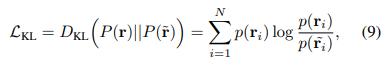
KL divergence 수식은 알던 것과 다르지 않다.
'약간 벗어난'은 $-5^\circ, 5^\circ$ 사이라고 명시한다.
4.4 Overall Objective

3가지 종류의 loss에 대해 $\lambda$를 이용해 가중치를 조정한다. Balancing term은, KL에 대해서는 5000 itertion마다 2배씩 감쇠한다고 5.2에서 언급한다. 근데 $\lambda_1$는 어떻게 한다는거야?...
5. Experiments
Experiments detail과 result에 대해서는 논문을 참조하라.
Few-shot task에 대해 기존에 존재하던 non-prior NeRF에 비해 성능이 좋다고 말한다.
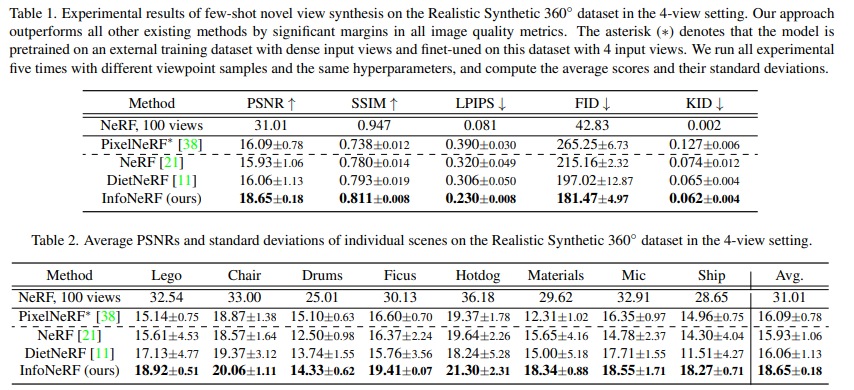
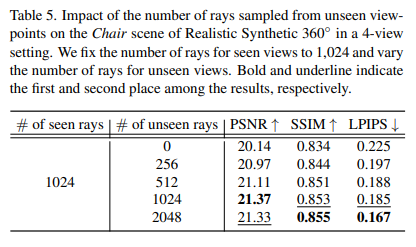
Table 5는 seen viewpoint의 ray를 1024로 고정했을 때, unseen viewpoints에서의 ray를 어떻게 조정해야 최적의 퍼포먼스가 나오는지 나타낸다. unseen array를 1024 내지 2048 정도로 하면 좋은 성능이 나왔다.

(a) seen view만을 이용했을 때, (b) seen view+unseen view를 이용했을 때 학습 결과를 보여준다. 노이즈가 줄어들어 깔끔한 이미지가 나오는 것을 보여준다.
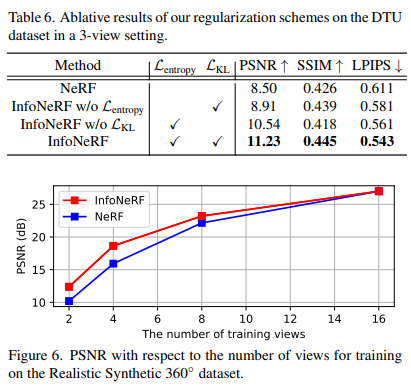
entropy loss, KL loss가 없을 때에 대한 ablation study이다. 둘 모두 중요한 역할을 한다는 것을 알 수 있다. 자세한 내용은 논문을 참고하라.
A. Validation for entropy loss and KL loss
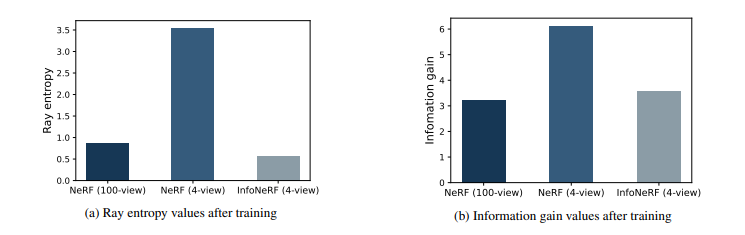
NeRF(100-view)와 NeRF(4-view)를 비교해 NeRF가 few-shot에 있어서는 noisier(무질서)한 이미지를 렌더링한다는 사실을 알 수 있다.
InfoNeRF(4-view)가 NeRF(100-view)와 유사한 수준으로 entropy와 information gain을 줄이는 것을 알 수 있다. 이는 설계한 loss가 잘 반영되었다는 증거이다.
C. Role of $\mathcal{L}_\text{KL}$ in Narrow-Baseline Data
narrow-baseline, 다시 말해 여러 이미지가 촬영 각도를 크게 바꾸지 않고 주어졌을 때(특히 MTU) KL loss가 특히 도움이 되었다고 말한다. 또한 entropy loss 없이 smoothing loss(KL loss)는 잘 작동하지 않았다고 한다.
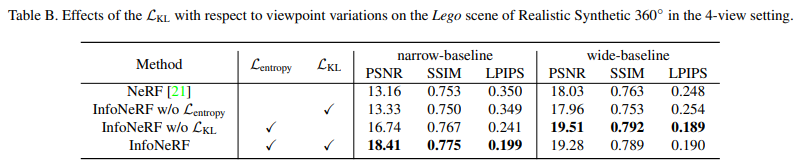

하나 이상한 것은 wide-baseline에서 w/o KL loss보다 InfoNeRF가 낮은 PSNR이 나왔다는 것이다. smoothing loss가 '항상 좋은 것'만은 아니라는 걸까...
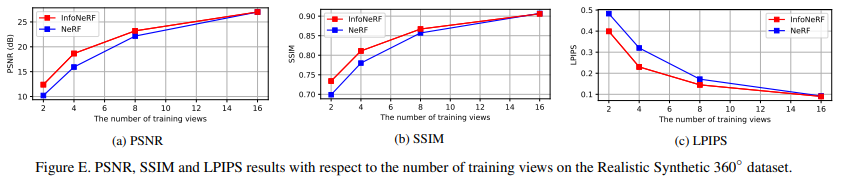
D. Robustness to the Number of Training Views
Training views를 늘렸을 때도 성능이 꿇리지 않는다는 것을 보여준다. 물론 16 view까지만 보여주지만..
E. Integration into Other NeRF-based Models
PixelNeRF와 mipNeRF에 InfoNeRF를 얹어서(아마 entropy loss, KL loss를 추가했을 듯하다) 성능이 향상됨을 보여준다.

