Describe, Explain, Plan and Select - Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
이 글에서는 Large Language Model(LLM)에 별도의 fine-tuning을 하지 않고도 LLM을 planner로서 활용해, planner-based method로서 처음으로 마인크래프트에서 다이아몬드를 캔 DEPS( Describe, Explain, Plan and Select)를 소개합니다.
LLM이 계획을 짜주면(planner), 계획의 sub-goal를 적당히 정렬하고(Selector), state와 현재 수행할 goal에 기반한 policy를 이용해 action을 수행하다가, goal failure이 나오면 현재 상태를 줄글로 묘사해(Descriptor) LLM에 넣고 실패 원인을 분석해(Explainer) 계획을 다시 짜는(planner) 형태이다. Policy 외에는 전부 줄글 형태로 다른 구성요소와 소통한다.
결국 LLM이 있고 적당히 하려고 하는 태스크에 쓸만하다면(물론 그렇지 않다면 적당한 조정이 필요하겠지만..) Selector, Policy, Descriptor만 신경 써서 만들면 된다. 이 연구에서 Selector, Policy는 Neural Network를 쓴 듯 보이고, Descriptor은 true information을 이용해 인간의 설계한 함수로 만든 것으로 보인다. (확실하진 않음)
Abstract
이 연구에서는 Minecraft의 planning problem을 multi-step reasoning으로 해결하기 위해 LLM에 기반한 interactive planning approach인 Describe, Explain, Plan and Select(DEPS)를 제시한다.
Abstract에서 제시하는, planning을 사용하는 agent들에 있어서 2가지의 primary challenge는 다음과 같다.
- Minecraft와 같은 open-ended world에서의 planning은 task의 long-term nature 때문에 정확하고 여러 스텝에 걸친 reasoning을 필요로 한다.
- vanilla planners는 parallel sub-goals를 정렬할 때 agent간의 가까운 정도를 고려하지 않아, 비효율적인 면을 보인다.
이 논문에서는 DEPS.를 이용해 long-haul planning에서 feedback을 통한 better error correction을 도모하고, goal Selector을 이용해 proximity 또한 고려하게 만든다. Selector은 parallel sub-goals를 얼마나 걸릴지에 기반해 랭킹을 매기는 learnable module이고 원래의 계획을 개선할 수 있도록 해준다.
이 논문의 접근을 통해 70개를 넘는 Minecraft tasks를 robust하게 달성할 수 있었는 multi-task agent를 처음 보여줬고, ablation and exploratory study를 통해 본 논문의 디자인이 상대방을 능가하는 방법을 자세히 설명하고 ObtainDiamond grand challenge에 있어 promising update를 제공한다.
1. Introduction
open-ended world에서 넓고 다양한 일을 할 수 있는 multi-task agent의 개발은 AGI로의 길에 있어 key milestone으로 보아져왔다. Minecraft의 많은 작업은 복잡한데, 예를 들어 build a bed라는 작업은 7개의 sub-goal을 포함하여 매우 긴 reasoning step을 필요로 한다.
또한 생성된 계획을 효율적으로 수행하는 것도 challenge이다. 보통 open-world environment에서 복잡한 계획은 여러 개의 parallel sub-goal을 포함한다. build a bed에 포함된 sub-goal 중 하나인 mine 3 woods, kill 3 sheep을 예로 들면, agent situation에 따라 mine wood -> kill shepp이 더 효율적일수도, 아닐수도 있다. 불행히도 표준적인 planner들은 이러한 sub-goal으로의 promixity를 고려하지 않는다고 한다.
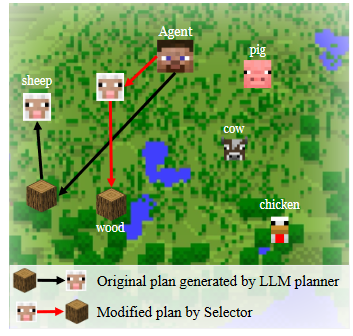
빨간 경로가 검은 경로보다 효율적이다.
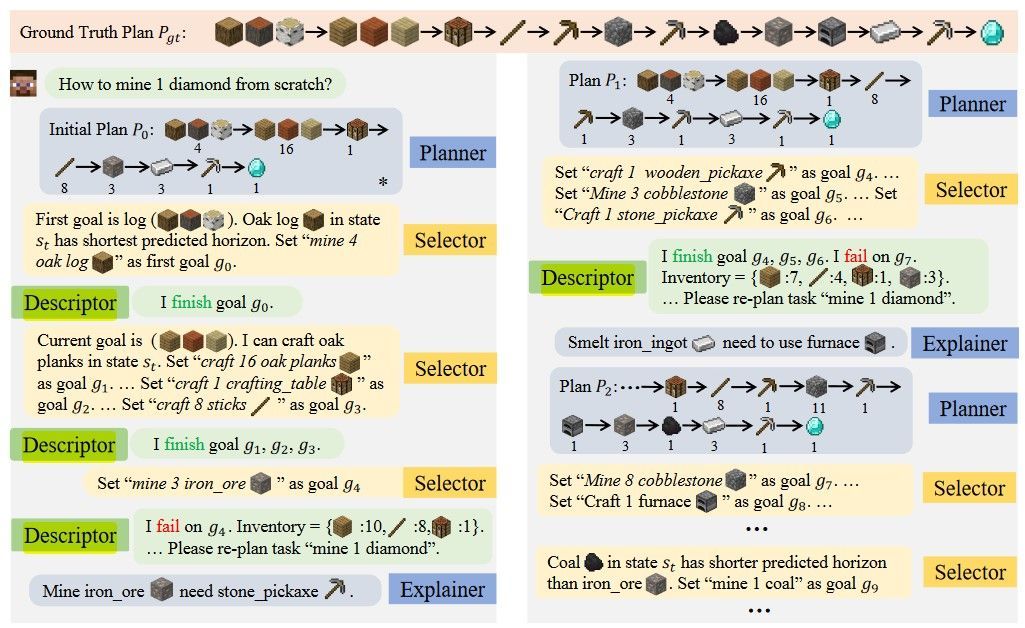
이러한 문제를 해결하기 위해 이 논문에서 Describe, Explain, Plan and Select(DEPS)를 제시한다. DEPS는, failture이 발생하면 descriptor이 현재 상황을 요약해 텍스트로서 planner로 보낸다. Planner은 그럼 explainer에게 이전 계획에 기반해 현재 상황의 에러를 설명하라고 하고, 마지막으로 planner이 계획을 맞도록 다시 짠다.
이러한 접근 방식으로 Minecraft task에서 전반적인 성공률을 52.74% 올렸고, 추가적으로 여러 개의 parallel sub-goal이 있을 경우 goal-selector이 proximity에 기반해 most-accessible sub-task를 골라 원래의 계획을 조화롭게 수정한다. 최종적으로 DEPS는 88.44%의 성공률을 보여준다. Minecraft의 71개 task에 대해 실험을 진행했으며 DEPS는 모든 baseline에서 거의 2배 이상의 성공률을 보여줬다.
또 DEPS는 ObtainDiamond task를 above-zero success rate로 수행한 최초의 planning 기반의 agent라고 한다. ('planning' 기반 중 최초이다. 이전에도 다이아몬드를 캔 RL agent들은 몇 있었다.) 'above-zero'라고 굳이 서술한 이유는 DEPS도 성공률이 그리 높진 않아서 above-zero라고 한 듯하다.
2. Background
$K$ sub-goal $g_1, \ldots, g_K$에 대해 goal-conditioned policy $\pi(a_t | s_t, g_k)$를 고려한다.
2.2 Challenges of Planning in Open Worlds
- long-term planning
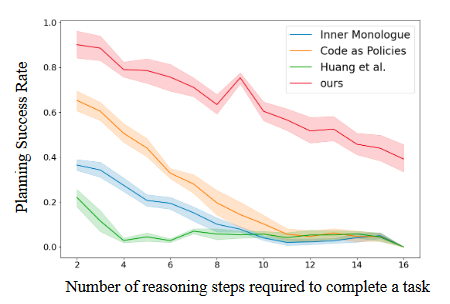
reasoning step이 늘어날수록 success rate가 급감하는 모습이다. DEPS가 가장 위에 있는 모습이다. - planning efficiency
위에서 계속 설명했던 parallel sub-goal에 관련된 ordering 이슈이다.
2.3 Planning with LLM
LLM은 task description $T$를 decode해 planner로써 일할 수 있다.
다만 이러한 접근의 potential deficit은 LLM-based planner이 environment에서의 feedback을 받지 못할 수 있다는 것이다. (이런 경우 non-executable, redundant plan이 나올 수 있다.) 이를 막기 위해 선행 연구에서는 affordance function, success detector, scene descriptor 과 같은 외부적인 요소를 이용해 LLM이 executable하게 계획하도록 "ground"했다.[1] 여기에 더해 Section 2.2에서 논의했던 대로 open-world domain의 partial observable한 성질이 LLM-based planner을 더욱 challenging하게 만든다.
3. Towards Reliable Planning in Embodied Open-World Environments
Section 3.2에 DEPS framework가 어떻게 agent에서 feedback을 받으며 plan을 반복적으로 만들지, Section 3.3에 Selector이 original plan을 proximity에 기반해 어떻게 더욱 최적화할지, Appendix C에 DEPS의 추가적인 implementation details가 있다.
3.1 DEPS Architecture
LLM을 zero-shot Planner로서 사용한다. 주의: LLM을 학습하지 않는다.
Given an instruction command(e.g. ObtainDiamond) as task $T$, LLM-based planner이 high-level task를 sequence of sub-goals ${g_1, \ldots, g_K}$로 추출한다. 이러한 sub-goal들 역시도 자연어의 형태로 기술된다.(e.g. mine oak wood)
많은 goal들에는 sequential한 성질이 있으나 parallel하게 수행해도 무방한 task들이 있다. 이러한 task들은 AND나 OR을 중간에 끼워넣어 기술된다. e.g. mine coal ∧ mine iron ore, mine oak wood ∨ mine birch wood. Selector이 이러한 parallel sub-goal을 보고 $s_t$에 기반해 suitable goal $g_t$를 고른다.
selected goal $g_t$은 low-level multi-task controller에 의해 실행된다. controller은 $\pi(a|s, g)$의 형태로 기술된다. 이 policy $\pi$는 RL, imitation learning으로 훈련될 수 있다.
그러나 initial plan $P_0$가 한번에 수행되지 않는 경우도 잦고 이런 경우 계획을 수정할 필요가 있다. 이를 위해, failure이 나타난 경우 Descriptor이 $s_t$와 가장 최근 목표에 대한 수행 결과를 요약해 text $d_t$로 만들어 LLM에 보낸다. LLM은 previous plan $P_{t-1}$의 에러를 self-explanation을 이용해 찾는다. 그리고 current task $T$에 대한 revised plan $P_t$를 만든다. 이러한 과정에서 LLM은 Explainer와 Planner의 역할을 동시에 수행한다.
Description: $d_t=f_{DESC}(s_{t-1})$
Prompt: $p_t = CONCAT(p_{t-1}, d_t)$
Plan: $P_t = f_{LM}(p_t)$
Goal: $g_t \sim f_S(P_t, s_{t-1})$
Action: $a_t \sim \pi(a_t|s_{t-1}, g_t)$
실험에서 Descriptor은 정확히 뭘 썼는지 언급하지 않았고(human feedback or fine-tuned CLIP이 가능하다고는 했는데, 뉘앙스를 보면 NN을 쓰지 않고 Minecraft에서 취득할 수 있는 true information 기반으로 사람이 디자인한게 아닐까 싶다..), Selector은 goal-sensitive Impala CNN을 이용한 horizon-predictive selector(HPS), Explainer&Planner은 LLM이 된다. Action은 뭐 대강 RL에 쓰이는 적당한 NN 쓰지 않았을까 싶다.
Descriptor은 정확히 어떻게 한건지는 모르겠지만 Minecraft의 true information 바탕으로 만든거라면 좀 실망스러울 것 같다. 예를 들어 goal $g$: 조합대 조합하기라면, 인벤토리 정보를 읽어와 조합대가 있으면 성공으로 넣었을 것 같은 삘이 좀 든다...
3.2. Describe, Explain and Plan with LLM Generates Executable Plans
현재 LLM-based planners들은 episode 시작에 LLM을 한번 query해 output plan을 episode 통틀어 사용한다. 당연히 이렇게 해서는 작업을 성공하기 힘들기에 feedback을 만들어주려고 하고, 다만 단순히 어떤 sub-goal이 완료되었는지 알려주는 것만으로는 계획의 오류를 고치기엔 부족하다.
구체적인 작동 예는 아래를 참고하는 게 좋을 듯하다. Figure 4에서 Explainer이 어떻게 작동하는지도 확인 가능하다. 다만 논문에서는 Explainer에 대해 To implement this, we provide few-shot demonstrations to the LLM as in chain-of-thoughts prompting라고 언급하는데, 정확히 뭔지는 인용 연구를 안 봐서 모르겠지만 아마 chain-of-thought 형태의 prompt를 미리 몇 개 제시해주면서 the current goal requires the use of an iron pickaxe, but the tool is not prepared in advance, or the current goal requires the use of 3 planks, but the currently available planks are not enough 과 같은 절차적인 사고를 할 수 있도록 few-shot learning을 유도하는 것으로 보인다.
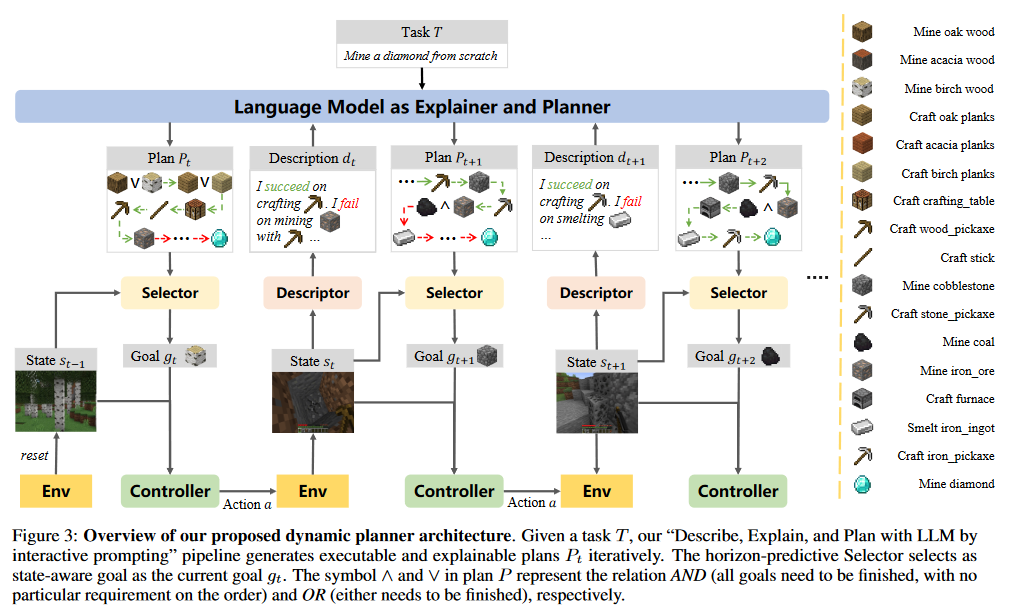
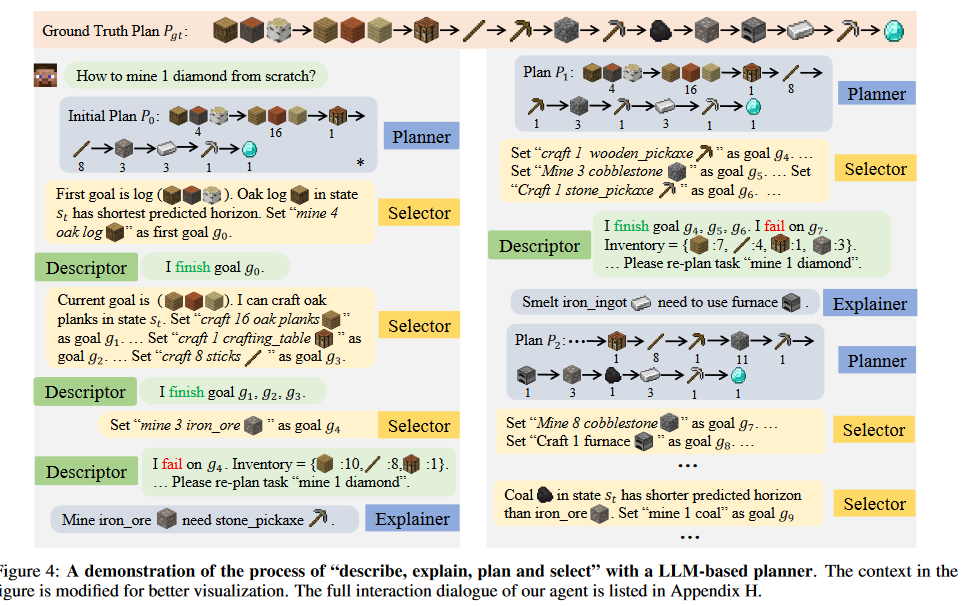
3.3 Horizon-Predictive Selector Yields Efficient Plans
Horizon-predictive selector(HPS)은 간단한데, horizon of a goal $h_t(g):=T_g-t$를 정의하고($T_g$는 goal $g$를 완료하는 시간) 이를 Neural Network $\mu$를 이용해 예측하는 방식을 사용한다. 그리고 horizon이 가장 작은 goal을 고르는 방식으로 보인다. 좀 더 좋은 방식이 없을까 싶은 생각이 드는 부분이다..
물론 HPS 말고 이외의 것을 Selector로 삼아도 무방하다. 관련된 ablation study가 후술되어있다.
4. Experiments
먼저 아래는 Minecraft Task101에 대한 설명이다.
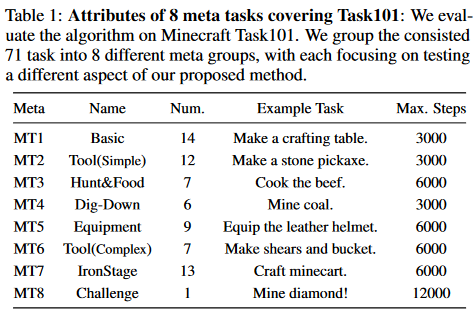
MT8이 대망의 다이아몬드이고, 나머지는 비교적 쉬운 목표이다.
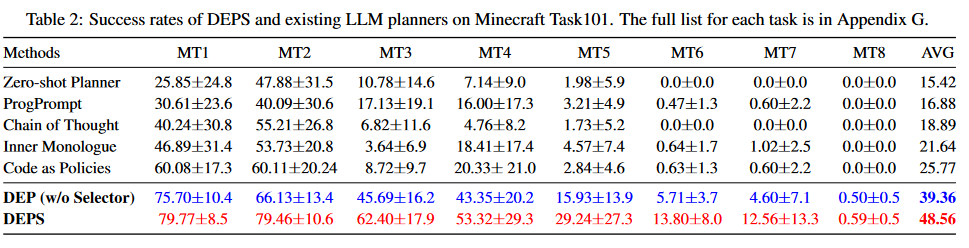
진짜로 다른 planner-based methods들은 MT8 성공률이 0.0인데, DEPS만 0.59인 것을 볼 수 있다. Selector이 워낙 새로운 요소이고 쉽게 탈부착할 수 있기 때문인지 있을 때와 없을 때의 실험을 모두 진행했다. 특히, MT7과 같은 efficiency-sensitive task를 할 때는 Selector을 사용하여 성공률이 2.7배 올라갔다고 논문에서 언급한다.
4.3 Ablation Study
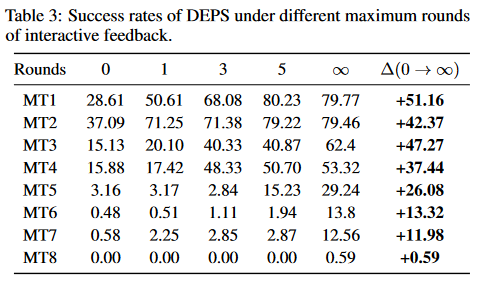
interactive feedback 숫자에 따른 퍼포먼스이다. feedback이 적으면 별 성능을 못 내는 것을 볼 수 있다.
planner을 사용하지 않은 다른 RL methods들의 다이아몬드 캐기에 대한 성공률도 언급하는데, VPT는 20분만에 다이아몬드 곡괭이를 만드는 것을 2.5%로 성공하고(근데 VPT는 '다이아몬드 곡괭이' 만들기고 MT8은 '다이아몬드 캐기'인데...? 뭐 다이아몬드 광맥이 보통 3개는 나오니 두 작업이 아주 큰 차이는 없겠지만서도 좀 이상하긴 하다.), DreamerV3는 training from scratch로 2% 성공률을 찍었다고 언급한다.
이에 대비해 DEPS는 10분 이내의 게임 플레이에서 0.59%의 성공률을 보여줬고, fixed LLM을 쓰며 특정한 fine-tune을 사용하지 않았다는 점에서 특기할만하다.
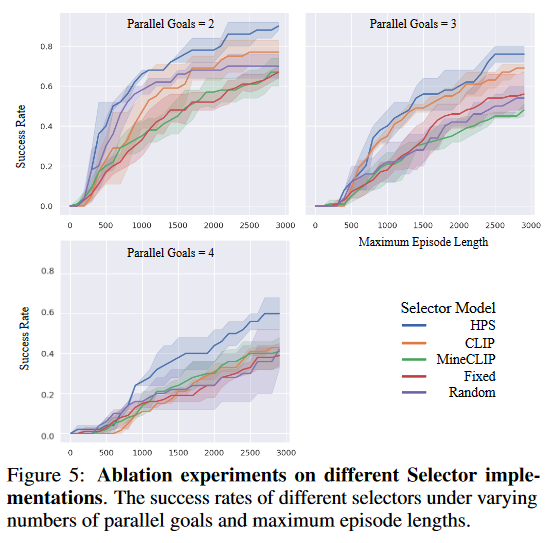
Selector의 선택에 따른 성공률을 그린 figure이다. Fixed, 즉 selector이 없는 것에 비해 확실히 높은 성공률을 보여주긴 한다. 좀 이상한 점은 MineCLIP이 CLIP보다 낮은 성공률을 보인다는 것이다.
5. Related Works
특이하게도 related works가 Section 5에 가있다. Task planning with LLM, Interactive Planning with LLM, Agents in Minecraft를 언급한다.
"ground"를 어떻게 한글로 직역할지 잘 모르겠다. 나름의 뉘앙스가 있는데,, ↩︎