2025년을 되돌아보며
2025년은 내가 ML 리서처로서 초입을 벗어나 궤도를 타게 된 한 해였다.
- 2024년 2월만 해도 팀에 리서처는 나 1명이었으나 여러 창구로 리쿠르팅을 진행한 결과 현재 리서처는 10명에 이른다. 이 중 현 연구 리더이신 윤성님을 포함해 내가 채용에 크게 관여하거나 "데려왔다"라고 말할 만한 인원이 대다수이다.
- 3월에 훈련소에 입소하여 여러 일들을 겪었는데, 아래 링크에 가서 읽은 책들을 정리해뒀다. 훈련소 이야기는 안 하고 책 이야기만 하는 이유는 뭐 좋은 이야기를 적을 게 없기 때문이다.
훈련소에서 읽은 책 후기
최근 3주동안 훈련소에서 읽은 책들 몇개 후기를 적어본다. * 용의자 X의 헌신, 히가시노 게이고 * 히가시노 게이고 본인이 자신이 쓴 글 중 최대의 역작이라 평가하는 글이라고 한다. 내가 읽어봤을 때도 정말 잘 쓰인 추리소설이라는 점에 대해 동의한다. * 스토리 플롯이 처음부터 끝까지 치밀하게 짜여져 있으며, 결론 역시, 나는 가상에 창작물에 대해 사회적인 정의는

- 5월-6월달쯤 AI agent의 성능이 생산성에 향상을 불러일으킬 수 있는 어느 기점(threshold)를 넘어섰다는 것을 경험으로 깨달았다. Copilot, Cursor, Augment Code, Codex, Antigravity와 같은 AI agent를 사용해봤으며 거의 5-10배에 달하는 생산성 향상을 체감하여 이전에는 절대 홀로 이룰 수 없는 성과들을 이뤄냈다. 특히 Augment Code를 6월달쯤 써봤을 때 즈음으로 생산성이 극도로 향상되었으며, 그때 주말 3일만에 1만줄을 넘게 코딩을 할 수 있었고 현재 내가 주로 개발했던 프로젝트인 open-world-agents는 이 레포의 내용 중 다른 레포로 분리된 내용이나 애초부터 분리하고 개발했던 내용이 꽤 많은데도 LOC 40만줄에 달한다.
- 특히, 개발 생산성과 관련하여, 코드가 유지보수 및 향상이 가능하기 위해서는 항상 어느정도 선(threshold) 이상의 퀄리티를 유지해야 한다. 이것이 만족되지 않으면 쓰레기 코드는 점차 더 많은 쓰레기를 낳기 때문이다. 하지만 AI Agent의 도움으로, 왠만한 주니어 개발자가 이렇게 짧은 시간에 쓸 수 없는 퀄리티 높은 코드를 뽑아내다보니 이것이 굉장히 쉬워졌다. 좋은 디자인, 좋은 컨벤션, 좋은 주석/docstring, 좋은 문서화에 내가 의사결정의 시간을 투자하면 디테일은 AI agent가 적절하게 구성해준다.
- 실제로 이제 나는 코드를 직접 쓰기보다 (1) 무엇을 구현할 지 생각하고, 그에 대한 스펙을 구체화하고 (2) 결과물을 보고 자연어의 형태로 리뷰하고 더 나은 형태를 고민하는 것에 대부분의 시간을 보낸다. 물론 필요한 경우 엄밀하게 구현의 정확성에 대해 검수하기도 하는데, 이것은 자동화된 테스트가 어려운 아키텍처 구현 등에 집중된 ML 연구 코드에서 보통 그렇고, 데이터 수집/eval 등 검수가 쉽고 자동화된 테스트가 가능한 경우는 코드를 한줄한줄 모두 읽을 필요는 없다.
- 말하자면 주니어치고 매우 괜찮은 코드를 작성하는 주니어 엔지니어 10명과 같이 일하는 시니어 엔지니어가 된 느낌으로, 아마 AI agent를 잘 쓰시는 엔지니어분들은 다 같은 느낌을 느꼈을 것이다. 당연히 이친구는 내가 말하지 않은 것도 알아서 잘 해주지 않는다. 하지만 그건 인간 주니어도 당연히 그렇다. "무엇을 구현할지"에 대해 좋은 계획을 세워 정확한 스펙을 전달하면 AI agent들의 성공률은 매우 높다.
- 내가 개발자로서 달성 가능한 최대의 업무 효율은 이미 달성했다고 생각한다. 내가 직접 키보드를 쳐서 코드를 쓰는 것보다 이미 AI agent에게 시키는 게 월등히 빠르다. AI agent에게 더 잘 시키는 방법을 고민해볼 수는 있겠으나 이미 어느정도 saturate되어 있다고 생각한다.
- 더불어 AI agent의 도움으로 아주 많은 성장을 했고, 앞으로 할 것 같다.
- Claude의 좋은 코드를 보고 매우 많이 배웠다.
- Coding agent뿐만 아니라 다른 AI agent를 이용해서도 매우 빠르게 정보를 습득하고 응용할 수 있는 초기 파이프라인을 구성했다. 이를 이용해 일주일만에 200개의 논문이 bibtex에 담긴 RFM(Robotics Foundation Model)에 대해 주요 organization/model/dataset과 여러 future research direction에 대해 논증된 서베이 논문을 만들어 팀 내에 공유하기도 했다. semantic scholar mcp, perplexity mcp, arxiv mcp등 여러 mcp를 활용했으며 1년 전 mcp에 대해 내가 "인간이 아니라 모델에게 맞춰주는 인터페이스로 정말 인간같은 모델이 나올 때는 쓰이지 않겠지만 지금으로서는 매우 파괴적인 에코시스템을 이룰 수 있는 디자인"이라고 논했던 것이 새삼 체감된다.
- 다만 아직 생태계의 곳곳에서 퀄리티가 부족한게 체감되긴 하는게 mcp의 특정 엔드포인트가 모종의 사유로 망가져버려도 AI agent가 무시하고 넘어가버리면 사용자가 알 수가 없고(이건 좀 명시적으로 알려주면 좋겠다...), 특히 mcp 각각을 봤을 때 퀄리티가 부족해 포크 후 수정이 필요한 경우가 몇몇 있었다.
- 연구자로서도 많이 성장했다-고 생각하는데, 아직 부족하다. 내년쯤 같은 이야기를 더 구체적인 이야기와 함께 할 수 있도록 노력하겠다.
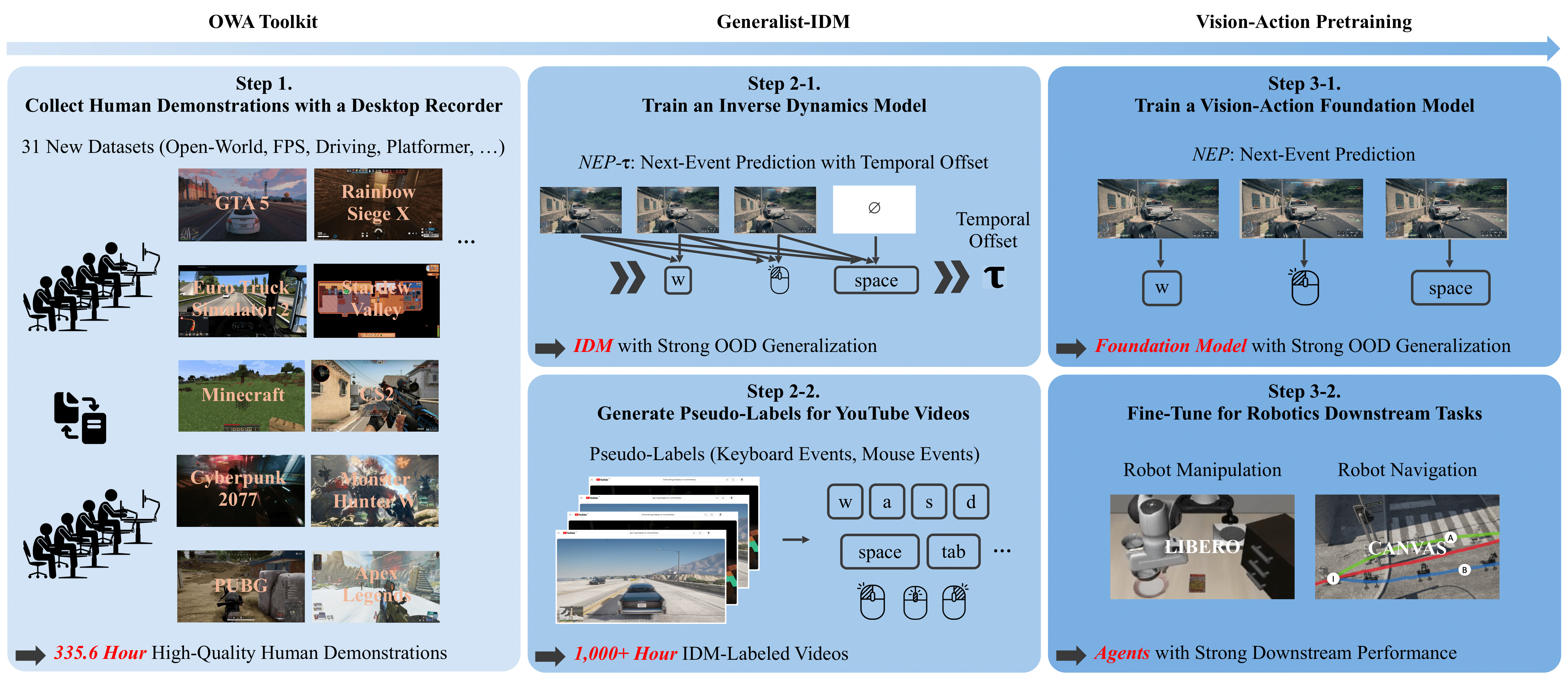
- 내가 리드한 두번째 연구인 D2E를 공개했다.
D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI
Desktop gaming data effectively pretrains embodied AI: 152× compression via OWA Toolkit, YouTube pseudo-labeling with Generalist-IDM, achieving 96.6% on LIBERO manipulation and 83.3% on CANVAS navigation with 1.3K hours of data.
- 원래 구상하던 것과는 좀 달라져서, 지금 버전도 마음에 안 드는 건 아니지만 시원섭섭하다.
- 사실 예전에도 CraftJarvis팀 연구 보면서 느끼기도 했지만 이 프로젝트 하면서 더 느꼈는데, 코딩이 매우 많이 필요한 연구는 아무리 열심히 작업해도 별로 알아주지 않는다. 학회에 주피터 노트북 1개로 재현 가능한 연구도 있을 정도로, 좋은 연구라고 많은 코드를 필요로 하지 않는 건 당연하다. 하지만 많은 코드를 필요로 하는 모험적인 연구를 할수록 엔지니어링에 자원이 소모되며 자연히 다른 곳에는 시간과 자원을 투자하기는 힘들어진다. 그리고 연구 커뮤니티는 이러한 현상에 대해 별로 인정해주지 않는다는 느낌을 받았다. D2E를 통해 OWA는 어느정도는 인지도를 얻고 조명을 받았을 것이다. 하지만 내가 노력하고 시간을 투자한 만큼 이 work의 가치를 진정하게 알아주는 사람은 심지어 같이 연구한 동료 중에도 없다고 느꼈다.
- 뭐 이러한 현상이나 사람이 잘못되었다기보다는. 그냥 섭섭하다. 앞으로 이런 사실에 너무 신경쓰기보다는 더 적은 엔지니어링 수고로도 더 큰 리서치 임팩트를 낼 수 있는 프로젝트에 집중하기로 생각했다.
올해에는 학교를 복학해야 한다. 동시에 논문도 가능한 많이 쓰려고 한다. 올해에는 엔지니어링 작업보다는 가설 검증 등 더 연구적인 부분과 좋은 writing/좋은 figure 그리기 등 더 "퀄리티 좋은 논문"을 쓰기 위한 활동에 더욱 집중하려고 한다. D2E의 figure들도 지금 under review인데 리뷰가 나오면 상당히 갈아엎으려고 한다. 동시에 내가 쓴 논문이 좋은 논문이어도 써놓고 가만히 있으면 아무도 알아주지 않기에, 어떻게 하면 내 work를 적절하게 잘 홍보할 수 있을지에 대해 집중하려고 한다.