인공지능의 미래에 대한 이야기 몇 단락: 2. 목적함수와 애벌레

이전 글: https://milkclouds.work/brief-look-at-ai-future/
o1, o3, inference time scaling
글을 쓰는 지금 이 시전, 2024년 12월 21일 오전 4시에는 o3에 대한 이야기가 많이들 나옵니다. OpenAI o1의 다음 모델인데, o2가 이미 상표권이 있어서 다음 버전 이름이 o3이라는 카더라도 있고요.
이전 글에서도 언급했지만, 저는 inference time scaling이 되는 날이 올 거라고, o1이 나오기 전부터 예상했습니다. 추론 근거가 된 자료는 다음의 2가지였습니다.
- 2024년 5월에 나온, 작은 크기의 디퓨전 모델이라도 추론 비용을 더 투자한다면 큰 크기의 디퓨전 모델과 같은 성능을 낼 수 있다는 논문입니다. 저는 이 논문을 보고 "특정 문제를 풀기 위한 최소한의 computation 분량"이 필요하다는 가설을 세웠고 지금도 이것이 강력하게 참일 거라고 생각하고 있습니다. 물론 여러 기법을 통해 어떤 문제를 풀기 위해 드는 연산을 줄일 수는 있겠으나, 물리적으로 더 줄일 수 없는 어떠한 bound가 존재할 겁니다.
- 참고로 저는 이러한 "물리적인 한계"에 매우 관심이 많습니다.
- Epoch.AI에서 작성한 리포트입니다. https://epoch.ai/blog/trading-off-compute-in-training-and-inference 2023년 7월에 작성되어 있습니다.
또 o1에 대한 생각을 12월에 더 구체화했었습니다. 근거가 된 글은 다음과 같습니다.
https://www.interconnects.ai/p/openais-o1-using-search-was-a-psyop
위 글에서는 learning to correct + longer inference context = o1이라는 추론을 합니다. (verifications and continuations) 저도 이런저런 복잡한 여러 모델 들어가는 시스템이 아니라고 생각합니다. MCTS도 같은 이치에서 기각이고요. 최소한 학습 시점에 명시적인 RL 기법을 사용했을지언정 추론 시간엔 아닐 거라고 생각합니다.
더 최근 들어서 o1에 대해서 정리된 제 생각은 다음과 같습니다.
- o1은 inference time computation을 scaling하면 성능 역시도 scaling된다.
- inference time scaling이 가능하기 위해서는 그것에 필요한 능력이 inference time 이전에 내재되어 있어야 한다. 즉, training time에 그러한 능력을 강조, 학습해야 한다.
- 다시 말해 training time에 그러한 능력이 모델에 내재되어 있지 않다면 inference time scaling은 불가능합니다.
- 그리고, train-inference의 2-phase로 나눠서 설명했지만 당연히 OpenAI에서 실험 및 모델 구축을 할 때에는 인간도 어느정도로 들어가는 루프를 여러 iteration 돌렸을 겁니다. (iterative improvement가 중요하다는 건, pretraining부터 관심 없던 사람들은 모를 수도 있지만, LLaMA 2 만들 때부터 알려져 있던 사실입니다. https://www.youtube.com/watch?v=NvTSfdeAbnU 에서 자세한 디테일을 확인 가능합니다. 최근 뉴립스에서 AI2에서 한 LLM tutorial도 좋고요.)
- 복잡한 테크닉, 복잡한 시스템은 일반적으로 scaling되지 않습니다. 또한 OpenAI 주변에서 돌아다니는 말들을 주워들었을 때도 복잡한 시스템을 사용한 것 같지 않습니다. 즉 OpenAI에서는 복잡하지 않지만 scaling이 잘 되는 어떠한 "세팅"을 찾았을 겁니다. 이 "세팅"이 너무나도 잘 scaling이 되기에 자신만만하고 디테일을 드러내지 않는 것일거고요.
- 누군가 OpenAI 외부에서도 closed-source 혹은 open-source로 이러한 "세팅"을 언젠가는 찾을 겁니다. 다만 그건 언제가 될 지 모르겠군요.
o1 => AGI?
다만, 그래서 OpenAI에서 AGI를 만들 수 있냐? 에 대해서는, 논쟁 거리가 좀 많은 것 같습니다. 일단 먼저 뜬구름 잡는 이야기를 해보죠.
머신러닝이란 뭘까요? 이미 경험이 있으신 분들은 다 알겠지만, "ML이 무엇일까"라는 설명에는 굉장히 할 수 있는 답변은 많지만 "ML을 하며 하는 일"은 결국 함수 최적화라고 요약할 수 있습니다. ML의 3요소는 (1) 모델 (2) 목표함수 (3) 최적화 알고리즘이고요, ML은 충분히 표현력이 있는 (1) 모델을 (2) 목표함수를 최대/최소화하는 방향으로 (3) 최적화 알고리즘을 이용해 최적화하는 총체를 이르는 학문입니다.
그리고 제가 알기로 이것에 해당하지 않는 예외는 없습니다. 인간이 pre-defined된 rule을 작성해 최적화 없이도 잘 작동하는 알고리즘을 만든다면 그건 애초에 rule-based라 부르지 ML이라고 부르지는 않고요, 일단 initial model은 아무것도 할 수 있는 일이 없죠. 최적화를 하면서 할 수 있는 일이 생길 뿐이고요.
그러면, (1) 모델 (2) 목표함수 (3) 최적화 알고리즘 중 무엇이 가장 중요할까요? 단연코, 무조건 (2) 목표함수가 가장 중요하며 다른 것들이 이미 많이 탐험된 지금은 사실상 (2) 목표함수"만" 중요하다고 폭력적으로 말해도 큰 무리가 없습니다. 당연히 나머지 둘이 안 중요한 건 아닌데 상대적으로 변경할 수 있는 여지가 굉장히 떨어지거든요. 모델은 Transformer, 최적화 알고리즘은 AdamW. 이거 말고는 "더 좋은" 선택이 될 수 있는 것이지, Transformer와 AdamW만 써도 왠만해서는 적당히 잘 작동합니다. 그러나, 목표함수는, 새로 풀고자 하는 문제가 있을 때마다 새로 만들어야 합니다.
목표함수의 개념은 differentiable, non-differentiable 모두에 적용됩니다. 좁은 의미의 딥러닝은 backprop이고 이건 differential objective인 NTP loss, denoising loss 등만 최적화 가능합니다. 하지만 RL과 같은 곳에서는 미분 가능하지 않은 임의의 목표함수에 대해서도 최적화가 가능한 formulation을 제공합니다.
또한 과거에는 굉장히 한정적인 형태의, 인간이 바로 정의가 가능한 목적함수에 대해서만 최적화가 가능했던 반면, 현재에 와서는 그걸 만든 인간도 머릿속에 상상이 되지 않는 복잡한 함수에 대해서도 최적화가 가능합니다. data-driven하게 학습하여 굉장히 복잡한 데이터의 분포 p(x)를 모델링하는 지금의 large generative model들도 그러한 예시이고요, 심지어 human preference라는 스칼라로 나타내어지지도 않는 값에 대해서 최적화를 하기도 합니다(RLHF, DPO와 같은 키워드로 들어보셨을 겁니다). human preference는 스칼라로 나타내어지지도 않아서 positive/negative의 pair data를 쓰기도 하죠. 옛날 같았으면 상상도 못할 일입니다.
그럼 뜬구름 잡는 이야기에서 다시 원래 이야기인 o1으로 돌아와봅시다.
o1은 그럼 어떤 목표에 대해 최적화를 하고 있을까요? 무한하게 self-improvement가 가능할까요?
딱히 그렇지는 않습니다. 그 이유는 위에서 줄곧 말하고 있던 목표함수 때문입니다.
수학, 코딩과 같은 태스크는 채점이 가능하며 비교적 목표함수가 잘 정의됩니다. 그러나 그렇지 않은 수많은 태스크들은 채점이 모호하고 목표함수가 잘 정의되지 않습니다. 오히려, 채점이 가능한 태스크보다 채점이 힘든 태스크의 수가 훨씬 많을 겁니다.
그래서, o1과 같은 inference scaling 기법들이 AGI를 만들 수 있냐고 하면 딱히 참은 아니라고 생각합니다.
사실 그리고 AGI라는 단어부터가 굉장히 기만적인 단어이기도 합니다. AGI에 대해 말하고 있는 사람에게, AGI의 정의에 대해 물어본다고 합시다.
어떤 사람 A는 "혼자서 검색하며 배울 수 있는 인공지능"이라고 할 수도 있겠죠. 그럼 저는 OpenAI API를 엮어서 OpenAI 모델이 자신이 모르는 내용을 찾고 finetune API를 돌려서 학습하는 파이프라인을 짤겁니다. 그럼 성공적으로 "혼자서 검색하며 배운다"를 달성하죠. 그럼 A는 다시 이렇게 되물을 겁니다. "아니 혼자서 성장했는지 알 수 없잖아요?" 그럼 저는 되물을 겁니다. "성장을 했다는 기준은 무엇으로 재나요?"
어떤 사람 B는 "사람보다 어떤 한 지점에서 뛰어난 인공지능"이라고 할 수도 있겠죠. 그럼 저는 이렇게 물을 겁니다. "그 '뛰어나다'의 정의를 어떻게 하나요?"
위의 이야기에서 공통점을 찾으셨나요? 결국 중요한 건 메트릭의 정의와 평가라는 겁니다. "~~을 만들 수 있나요? ~~을 할 수 있나요?" 라고 하면 다 만들 수 있고요 다 할 수 있습니다. 어떠한 질문에도 답을 줄 수 있는 인공지능을 만들 수 있을까요? 네, 만들 수 있죠. 임의의 입력에 대해 0을 반환하는 함수를 만들면 됩니다. 아주 빠르게 잘 답변하겠죠. 중요한 건 잘 정의되는 어떤 메트릭에 대해 "이 메트릭의 특정 수치를 넘을 수 있나요?" 겠죠. 그렇게 하는 것만이 채점이 가능하니까요.
아무튼, 그래서 저는 OpenAI 연구자들이 어떠한 범주까지를 inference time scaling을 하며 고려하는 태스크로 보고 있으며 어떠한 범주까지를 self-improvement시킬 것인지가 궁금합니다. 수학, 코딩은 지금보다 훨씬 잘할 수 있게 될 수 있겠죠. 그런데 나머지는 어떨지가 궁금합니다.
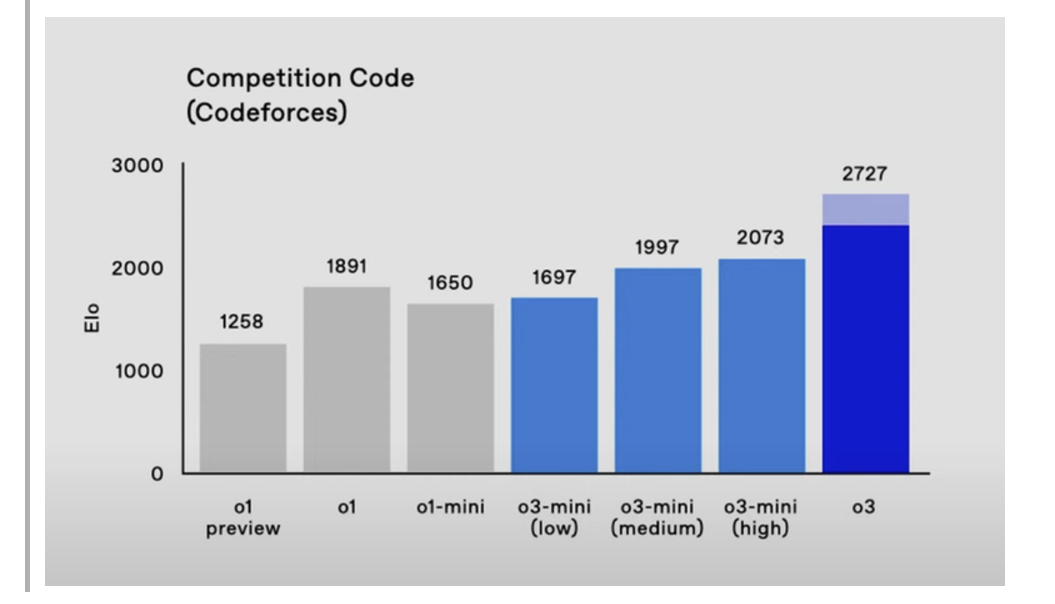
물론, 최상단에 올린 o3 Codeforces 성적이 사실이라면 엄청나다고 할 정도로 뛰어나진 건 맞습니다. 2700점이면 레드일텐데 그럼 인간계 최강급이라고 봐도 무방할 텐데요...
OpenAI에서 놓치고 있는 것들
그리고 또한, openai에서 놓치고 있는 것들 또한 존재합니다. OpenAI에서는 language modality 위주로 엄청난 사고능력을 가진 인공지능을 만드는 것을 거의 유일한 주된 목표로 삼고 있습니다.
하지만 인간은 (1) 멀티모달 입력을 처리하며 (2) 행동을 할 수 있습니다. 이 둘은 굉장히 큰 차이점을 만들며 또한 지금의 OpenAI 모델들이 비전 입력도 받으며 행동도 할 수 있음에도 굉장히 많이 모자라다고 생각할 수밖에 없는 이유가 됩니다.
당신이 손을 뻗어 유리컵을 집어 올리려고 한다고 합니다.
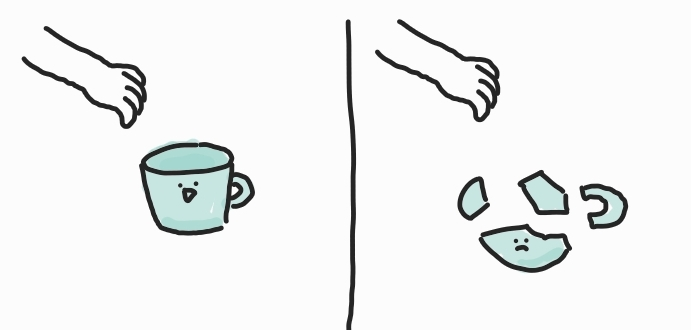
- 그럼, 눈으로 유리컵을 보며 손을 뻗습니다. 이때, 당신은 아주 자연스럽게 유리컵에 손이 덜 다다랐다면 손을 더 뻗고, 유리컵보다 손이 더 갔다며 손을 덜 뻗으며 손의 위치를 조정합니다. 이때 중요한 건 visual feedback의 요소입니다. 즉 한번 보고 행동하는 게 끝이 아니라, 행동을 하며 동시에 visual observation을 입력으로 받고 이러한 루프를 매우 빠르게 반복합니다.
- 유리컵을 잡습니다. 이때, 너무 약하게 잡으면 유리컵이 미끄러져 내려 깨질 수도 있고요, 너무 세게 잡으면 유리컵이 깨질 수도 있습니다. 이때 중요한 건 haptic feedback의 요소입니다. 위와 마찬가지로 observation에 한번 받고 action을 쭉 하는 게 아니라, observation-action 루프를 계속 반복하며 적절한 힘을 찾습니다.
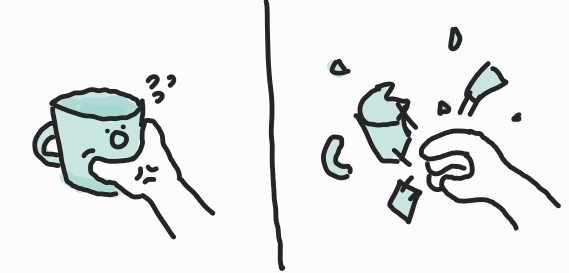
종합하자면 환경에 대한 피드백을 받아 행동하는 것이 중요하다, 입니다. 연구자들은 observation 한번에 대해 action 하나를 내뱉는 것만으로 모든 태스크를 풀 수 있다고 막연히 착각하고 있는 경우가 많습니다. 하지만 절대 아닙니다. 왜 "절대"인지는 사실 별로 설명할 필요는 없겠지만 말하자면 물리적인 한계가 있으니까 그렇죠. 받지 않은 정보는 모른다는 물리법칙이요. (feedback을 받지 않고 feedback을 받아야만 알 수 있는 정보를 알 수 있을 리가 없죠.) 이건 당연하게도 테크닉을 잘 적용한다거나 해서 풀 수 있는 문제가 절대로 아닙니다. 실제로 observation-action의 sequence를 멍청하게 전부 입출력으로 받아서 처리해야만 풀 수 있는 문제입니다. 즉 막대한 양의 observation을 멍청하게 다 입력으로 넣어줘야만 합니다.
하지만 이때 문제되는 것이 있습니다. 바로 vision modality의 무거움입니다. 현재 거의 스탠다드로 사용하는 MLLM 방법론에서는 이미지 한장에 대해 100~200 토큰 정도를 할당합니다. 그럼 이미지 한 장당 토큰 수를 144로 두고, 인간이 보는 모니터처럼 대충 60FPS의 모니터 출력을 10초동안 받는다고 해보죠 .그럼 144 * 60 * 10=86400 토큰이 필요합니다. 그런데, 현재 대다수의 모델들이 받는 토큰의 context length를 4K와 같은 Killo(1000) 단위이고 Gemini가 정말로 예외적으로 1M 토큰을 받을 수 있어 유명했었죠. 다시 말해, 현재 MLLM 아키텍처 구조로는 10초 영상도 받기 힘듭니다. 10초를 받을 수 있다고 해도 86K의 막대한 양의 토큰을 처리하려면 엄청난 시간이 걸리기에 별로 의미가 없고요. (그렇기에 이를 해결하기 위해 FastV 등 token eviction, token merging을 하는 방법들이 존재는 하나, 근본적인 문제를 해결하지는 못합니다.)
이것을 해결하기 위해서는 근본적으로, 아키텍처 scaling 방향성부터 고쳐야 합니다. 지금처럼 (1) 고차원적인 reasoning 능력을 강조하지 않고, (2) 한 토큰의 가치(한 토큰에 대응하는 학습/추론 비용 등)을 내리고, (3) 극도로 긴 context에 대해서도 효율적으로 처리할 수 있어야 합니다. (1)은 당장 이러한 부분을 기대할 수 없고 또한 단기적인 문제 해결에 저해가 될 것으로 예상되기에 언급한 것이지만, 아주 긴 미래를 본다면 물론 해결되어야 하는 문제입니다. 이러한 맥락에서 Meta에서 최근 공개한 BLT는 매우 promising한 방향이라 보고 있습니다.
또한, 데이터 역시도 지금처럼 internet text data를 이용한 scaling이 아니라 video에 기반한 scaling을 해야 합니다. 인터넷에 있는 영상도 가능하겠지만, 제가 눈여겨보고 있는 것은 Meta의 Project Aria와 같은 egocentric video와 키보드/마우스가 곁들여진 데스크탑 데이터입니다.
이런 화두를 던져보고 싶네요. 고차원적인 사고를 할 수 있지만 언어만을 입출력할 수 있는 컴퓨터에 갇혀 있는 AGI와, 현실 세계에서 움직일 수 있는 실제 애벌레와 똑같은 애벌레 AI, 둘 중 뭐가 "우월"한가요? 물론 "우월" 같은 건 없습니다. 하지만 지금까지 사람들은 전자에만 집중해왔고, 후자에는 거의 집중해오지 않았습니다. 하지만 생명체들은 진화적으로 시각을 먼저 배운 후에 언어와 같은 고차원적인 개념을 배웠고, 이는 지금의 LLM들과 정반대입니다. 후자가, 정말로 "열등"할까요?

물론 이러한 방향성이 주목받는 것은 어려운 일입니다. 이미 사람들의 AI에 대한 기대감은 높아져 있고, 그들이 사람처럼, 혹은 사람을 뛰어넘는 성과를 보여주는 것에만 관심이 있습니다. 여기에서 처음으로 되돌아가서 멀티모달을 다룰 수 있고 행동을 할 수 있지만 벌레같은 지능을 가진 AI를 만들자고 하는 것은 어려운 일입니다. 만들어도 주목을 크게 받지 못할 수도 있고요.
그리고 OpenAI에서 "놓치고 있다"라고 이야기는 했지만 이미 에이전트에 많은 관심을 기울이고 있고 엄청나게 뛰어난 연구자들이 있는 회사인 만큼 당연히 염두에 두고는 있을 거라고 생각합니다. 단지 대외적으로 덜 강조하고 있을 뿐.
저는 회사에서는 고등한 지능이 필요하지 않은 주행 에이전트를 만들며 개인 프로젝트로는 고등한 지능이 필요하지 않은 게임 에이전트를 만들고 있습니다. 뭐 대강의 이야기는 끝났고요, 이 글의 주제와 관련된 랜덤한 이야기 나누고 싶으신 분들은 언제든 연락 환영합니다.
