Machine Learning 인공지능의 미래에 대한 이야기 몇 단락: 2. 목적함수와 애벌레 이전 글: https://milkclouds.work/brief-look-at-ai-future/ o1, o3,
Machine Learning 인간과 같은 에이전트를 만들어야 하는 이유(feat. robotics) 저는 현재 마음AI에서 차량 및 로봇 자율주행 에이전트를 개발하고 있습니다. 사이드프로젝트로는 OpenSIMA라는
Machine Learning 인공지능의 미래에 대한 이야기 몇 단락: 1. 무엇이 병목인가? 이야기를 하기에 앞서: 일단, 기본적으로 이 글은 scaling law가 인공지능의 미래를 논함에
Machine Learning Practical Tips for Machine Learning Engineers Linux * 리눅스나 운영체제 관련된 많은 것들을 알고 있으면 가끔씩 도움이 됩니다. * UFS,
Machine Learning 딥러닝 입문부터 심화까지 강의,책,공부소스 추천(개정4판) 딥러닝이란? 개쩌는 비선형함수입니다. 농담이고, 간단히 설명하자면 인간의 뉴런을 모방해 신경망을 깊게 쌓아올려
Machine Learning stable-diffusion-webui 설치하고 DreamArtist 돌려보기 주: feature image는 아래 과정을 따라 만들었음 1. stable-diffusion-webui 설치
Machine Learning Pytorch DDP 설정하는 법 (DDP baseline) 일단 아래는 baseline으로 쓸만한 데모 소스이다. (설명은 더 아래에 있다.) NLP 모델에서
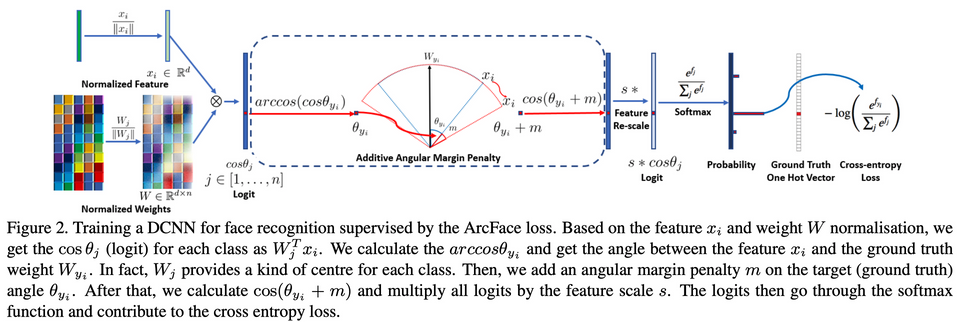
Machine Learning ArcfaceLoss for Competition ArcfaceLoss는 간단히 말하면 Softmax+Cross Entropy Loss(CE Loss)를 개량한 것이라
Machine Learning [딥러닝] 이상하게 길게 보면 학습이 되는 것 같긴 한데 영 상태가 이상할 때 해결방법 이런 식으로 수십 epoch 이후에는 성능 향상이 되기는 하는데 단기적으로는 심지어 loss가
Papers Reading InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering https://arxiv.





![[딥러닝] 이상하게 길게 보면 학습이 되는 것 같긴 한데 영 상태가 이상할 때 해결방법](/content/images/size/w960/2022/07/------2022-07-19-000842.png)
