Pytorch 문제해결노트
pytorch 사용 도중 마주한 여러 오류와 그 해결책을 기록한다.
- [0,1] RGB 대신 [0, 255] RGB 입력
[0,1] 범위로 바꾸지 않고 이미지를 Faster R-CNN에 넣으니까 gradient exploding 일어나서 loss가 무한대로 가더라... 도대체 왜 이러지 하루 동안 고민했는데, 이게 더 어이가 없는 게 랜덤 시드가 잘 걸리면 아예 똑같은 소스코드로 훈련을 2번 돌려도 한번은 gradient explode가 일어나고 한번은 어찌어찌 학습이 된다. 그것도 잘 된다. 분명 pretrained model 받아서 fine-tuning하는건데 도대체 왜 fine-tuning할때는 [0,1]로 안 바꿔줬는데 학습이 되지??? 하는 의문도 드는데 그러게 왜 될까?
이걸 왜 착각했냐면, 어디선가 Faster R-CNN 내부에서 정규화(표준화)을 한다는 말을 본 것 같아서 그렇다.. (이미지 크기를 조절한다는 걸 잘못 봤나..) 또 나의 착각을 유발한 게 하나 더 있는데, 기존 baseline 코드(대회 도중 발견한 오류다)에서는 pillow로 이미지를 로드하고 transform = transforms.Compose([transforms.ToTensor()])를 실행한다. 나는 이 줄을 지우고 cv로 이미지를 로드해 직접 permute해서 채널 순서를 맞추고 토치 텐서로 만들었었다.
baseline 코드에서 겉보기에 [0,1] 범위로 바꾸는게 안 보여서 몰랐는데.. transforms.ToTensor()은 [0, 255] 범위 pillow 이미지가 입력으로 들어오면 자동으로 [0,1] 범위로 바꿔준단다. 난 baseline 코드에도 정규화가 없는 줄 알았지...
꼭 입력 데이터를 잘 확인해 필요하면 A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])를 해주자. (A: albumentation)
- evaluation할 때만 cuda out of memory가 나는 이슈(training은 멀쩡)
분명 training할 때는 CUDA 메모리가 거의 꽉 찼어도 메모리 초과는 안 났는데 evaluation할 때 CUDA out of memory가 나는 현상을 마주했다.
아니 model.eval()도 했는데 도대체 왜 이러지? 싶었는데, model.eval()은 with torch.no_grad()와 같은 효과가 아니라고 한다. 단지 evaluation time에 다르게 작동하는 모듈들에게 알려주는 용도라고..
 study&grow
study&grow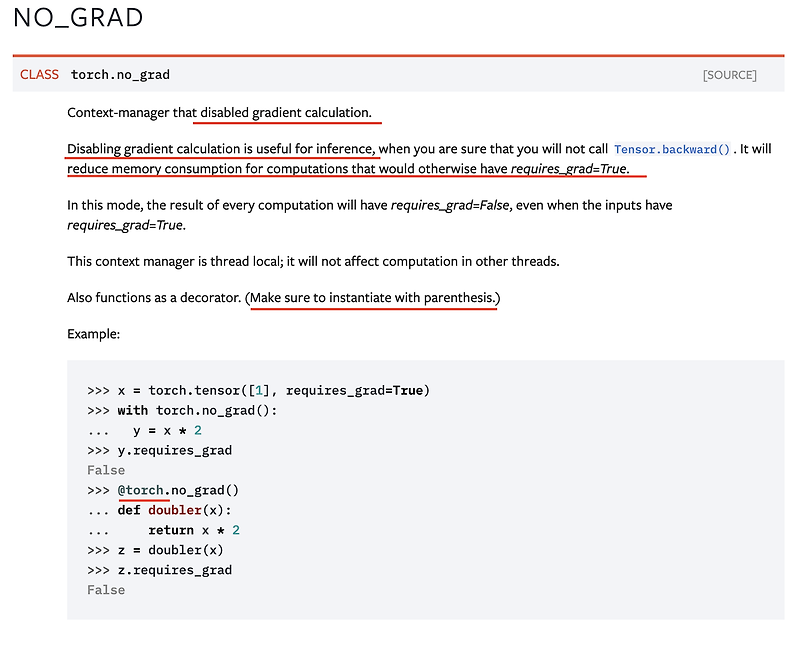
- Faster R-CNN의 dataparallel
Faster RCNN 사용할 때 DataParellel을 썼더니 size mismatch 오류가 났었다.
RuntimeError: The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 0
 pytorch
pytorchdetection 계열 모델 중 DataParellel과 호환이 안 되는 게 있나보다....
덤으로, 관련해서 구글링하다보니 DataParallel이 complex-valued tensor을 지 맘대로 real-value로 바꿔버려서 오류가 났다는 이야기도 있던데 좀 어이가 없었다. 전세계 수십만명이 쓰는 pytorch에서도 저런 불완전한 게 있다니... 뭐 이상할 것도 없지만. 멀티쓰레딩이 아닌 멀티프로세스를 쓰는 DistributedDataParallel을 사용하면 괜찮다고 한다.

