DETR: End-to-End Object Detection with Transformers(ECCV 2020)
요약
정해진 개수의 bounding box를 구하고, bipartite matching을 통해 ground truth box와 매칭시킨다. 이후 loss를 구한다. 이런 과정을 통해 NMS(Non-maximum Suppression) 등과 같은 작업 없이 End-to-End로 Object Detection을 수행할 수 있다. (정해진 개수보다 적은 bounding box가 이미지 내에 존재한다면 'no object' class에 적절히 대응시킨다.)
또한 Encoding, Decoding 과정에서 Transformer을 사용한다.
논문에서는 bipartite matching losses for set prediction, encoder-decoder architectures based on the transformer을 썼다고 말한다.
Two ingredients are essential for direct set predictions in detection: (1) a set prediction loss that forces unique matching between predicted and ground truth boxes; (2) an architecture that predicts (in a single pass) a set of objects and models their relation.
0. 선행지식
이분 매칭(bipartite matching), Transformer(Attention Is All You Need(NIPS 2017))
이분 매칭의 대표적인 알고리즘이 Hungarian algorithm이다.
1. Introduction
Vision Task에서 predicting set of bounding boxes는 간접적인 방식(large sets of proposal, anchors, window center)으로 이루어져 왔다. 이렇게 했을 때, near-duplicate prediction을 어떻게 처리할 지에 대한 post-processing이 performance에 큰 영향을 주었다.
NLP와 같은 다른 task에서는 end-to-end philosophy가 적용된 바 있으나 vision에는 아직 그렇지 않고, 이 논문에서 그러한 방식을 제시한다.
elements in sequence에 대해 all pairwise interaction을 명시적으로 모델링하는 self-attention 연산은 duplicate bounding box를 없애는 데 적합하다.
predicted와 ground truth object 사이 bipartite matching을 수행하는 set loss function을 정의해, spatial anchors와 NMS 같은 사전 지식 없이 end-to-end로 작업이 수행될 수 있도록 한다.
(필자의 첨언) 이것은 "여러 bounding box는 겹쳐 있으면 안된다"는 사실을, NMS와 같이 명시적으로 따로 정의된 방법이 아니라 ground-truth를 bipartite matching시킴으로써 간접적으로 가르치는 것이라고 볼 수 있다.
특히 transformer은 large objects를 detect하는 데에 faster r-cnn에 비해 강점을 나타내는데, 이는 attention의 non-local한 특성에 의한다.
그러나 small object를 detect하는 데에는 상대적으로 약점을 드러낸다. (Deformable DETR에서 개선)
2.1 Set prediction
Hungarian Algorithm을 이용한 bipartite matching으로 set-prediction에 대한 loss를 정의한다.
2.2 Transformers and Parallel Decoding
Transformer의 Encoder-Decoder Architecture을 가져다 쓰되, set prediction에 필요한 global computation을 하기 위해 parallel decoding을 한다. (decoding layer의 output을 한번에 얻어낸다고 이해함)


이곳 중간에 보면 Augoregressive 방식과 Parallel 방식이 어떻게 다른지 그림을 통해 바로 이해할 수 있다.

3. The DETR model
3.1 Object detection set prediction loss
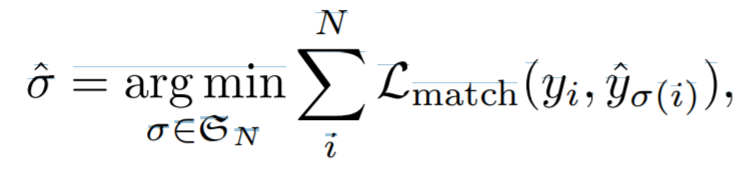
bipartite matching 도중 사용한 cost
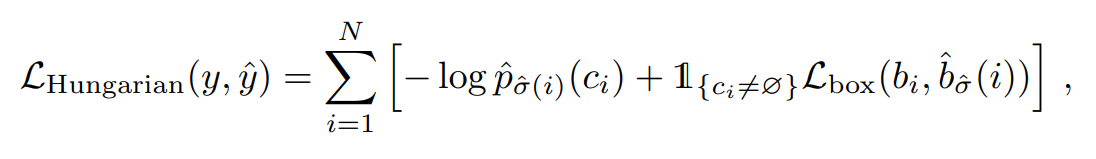
bipartite matching losses for set prediction
bipartite matching 도중 사용한 cost와 bipartite matching losses가 수식이 다름에 유의하자. 논문을 보면 empirically 더 낫고 scale이 맞아서 그렇다, 이런 식으로 설명이 되어 있다.
Bounding box loss는 IoU loss(1-IoU)와 l1 loss의 가중합으로 구성된다. 가중치는 hyperparameter이다.
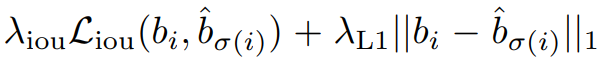
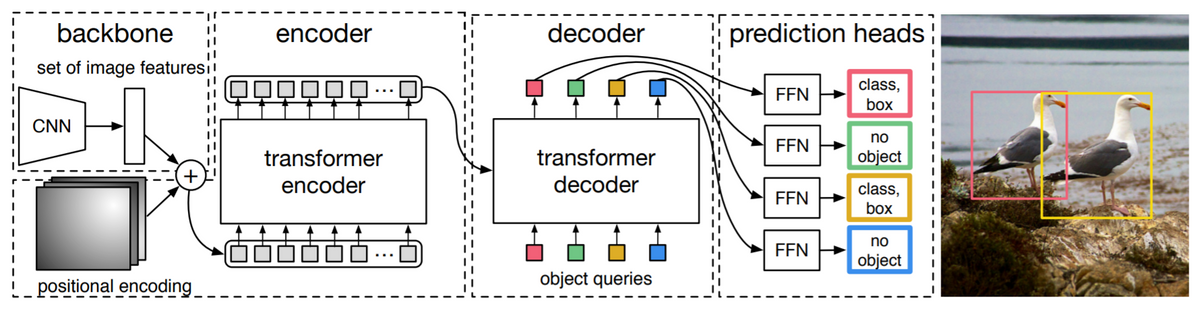
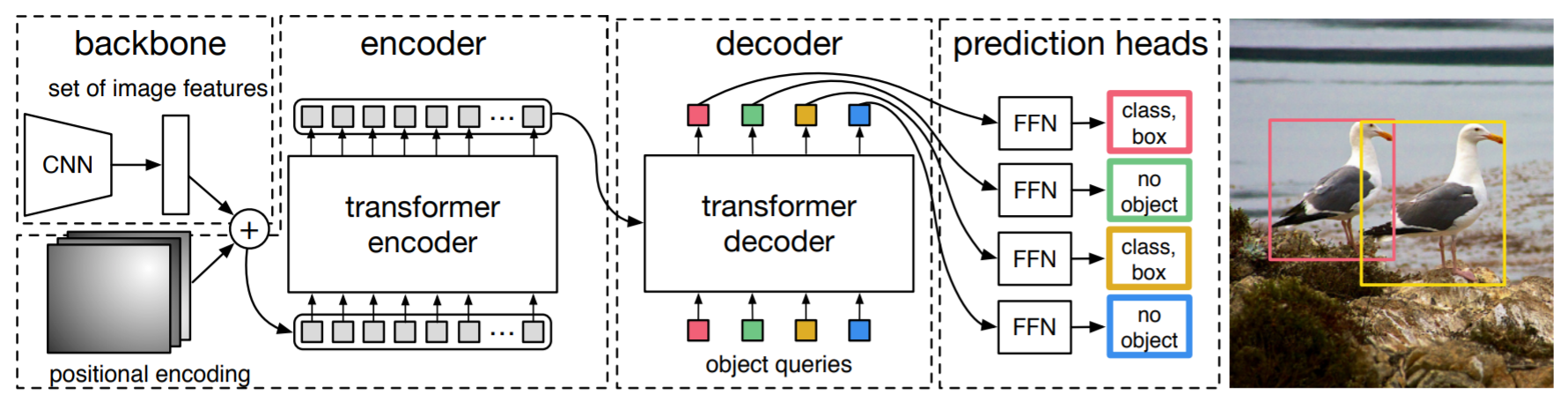
3.2 DETR architecture
backbone에서 image feature을 뽑아내고, encoder에서 globally reasoning을 보강하고, decoder에서 object queries들을 예상한 후, FFN에서 bounding box를 뽑아낸다. 아래는 각각에 대한 특이 사항이다.
- Backbone: channel을 늘려주고 resolution을 적절히 줄여주는 CNN을 사용한다.
- Transformer Encoder: 특이사항 없음
- Transformer Decoder: decoder이 permutation invariant하기에 초기값이 서로 달라야 한다.
- FFN: null object가 있다.
- Auxiliary decoding losses: decoder 뒤마다 auxiliary loss(prediction FFN, Hungarian loss)를 추가해 duplicate bounding box가 쳐지지 않도록 돕는다. 각각의 decoder 뒤의 FFN은 weight를 공유한다. Auxiliary classifier의 개념은 GoogLeNet에서도 제시된 바 있으며, 망이 깊어질 때 앞쪽에도 gradient를 효과적으로 전파하기 위해 쓰인다.
4.2 Ablations
- Number of encoder layers
- 특히 encoder layer가 없을 때 large object 처리를 잘 못했다. encoder가 global scene reasoning에서 disentangling objects에 중요해서 그렇다고 가설을 세웠다 한다.
- encoder layer가 깊을수록 AP가 올라갔다. (Table.2)
- Fig.3은 특정 픽셀이 어디에 attention을 높게 두는지를 나타낸다. 해당 객체에 잘 집중하고 있음을 확인할 수 있다.

- Number of decoder layers
- decoder layer가 적을 때는 NMS를 적용했을 때 performance의 향상이 있었지만 decoder layers가 많아질수록 NMS의 영향도가 적어졌다.
- decoder layer가 많을수록 AP가 올라갔다.(Fig.4)
- Fig.6은 디코더에서 어디에 attention을 두는지를 나타낸다. decoder에서 bounding box를 예측함에 기여해서 그런지, 물체의 말단 부위에 집중하는 것을 알 수 있다. (필자의 첨언) 특히 bounding box의 말단이 아닌 '물체의 말단'에 집중한다는 점에 착안해, instance segmentation에의 응용도 가능할 것이라 예상할 수 있다. 역시나 논문(1, 2)이 이미 있으며 이미 본 논문에서도 panoptic segmentation에의 사용 방법을 서술하고 있다.

-
Importance of FFN
- 마지막 레이어를 1x1 convolution, FFN으로 두는 것이 중요하다. self-attention이 자기 자신만을 집중하게 만들기 쉽지 않아 그런 듯.
-
Importance of positional encodings
- positonal encoding을 여러 방식으로 해봤을 때, sine at attn. 을 transformer encoder+decoder에 적용하고 디코더의 output pos encoder도 learned at attn.으로 두는 것이 최적이라 한다. sine at input은 input에만 인코딩, ~ at attn.은 attn 레이어마다 인코딩하는 것을 뜻한다. 자세한 구조는 A.3의 그림 참고.
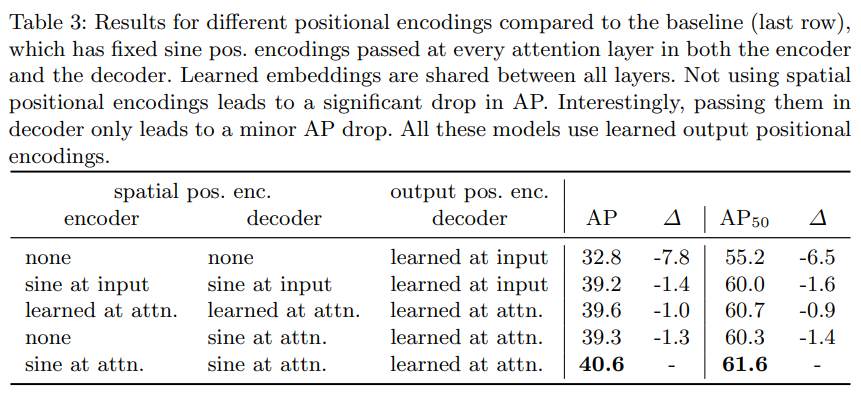
- positonal encoding을 여러 방식으로 해봤을 때, sine at attn. 을 transformer encoder+decoder에 적용하고 디코더의 output pos encoder도 learned at attn.으로 두는 것이 최적이라 한다. sine at input은 input에만 인코딩, ~ at attn.은 attn 레이어마다 인코딩하는 것을 뜻한다. 자세한 구조는 A.3의 그림 참고.
-
Loss ablations
- l1 loss와 GIoU loss를 모두 사용하는 것이 가장 AP가 높았다.
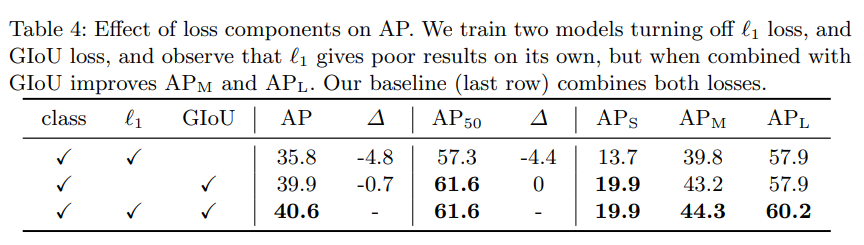
- l1 loss와 GIoU loss를 모두 사용하는 것이 가장 AP가 높았다.
4.3 Analysis

특정 query slot이 주요하게 예측하는 이미지의 부분이 있었다. 그리고 모든 slot에서 image-wide box(빨간 점)을 예측하는 mode가 있는데 이는 COCO 데이터셋의 특성에 의한 영향으로 가설을 세웠다.
4.4 DETR for panoptic segmentation
panoptic segmentation이란 stuff와 thing을 모두 segmentation하는 vision의 task이다. stuff란 쉽게 말해 돌로 된 뭔가, 하늘 등 불가산(셀 수 없는)의 무언가, thing은 의자, 사람 등 가산(셀 수 있는)의 무언가라고 생각하면 된다.
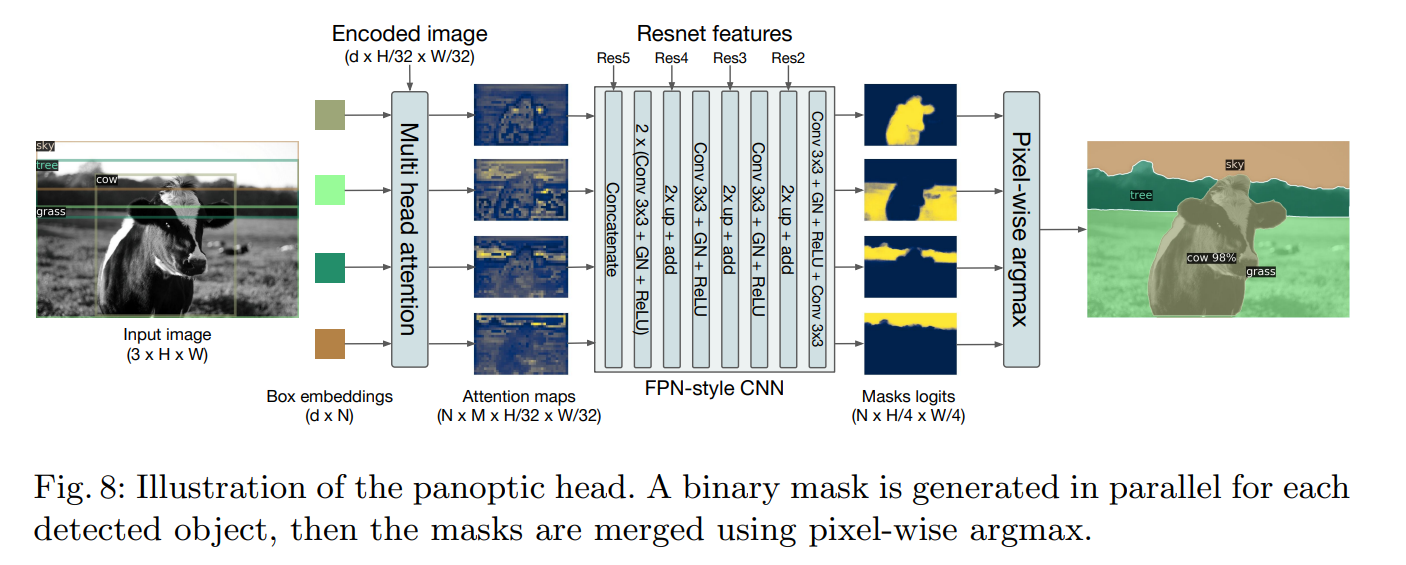
Attention maps에 FPN을 돌린 후 argmax해서 panoptic segmentation을 하는 것을 나타내는 그림이다. DETR 특성상 panoptic segmentation을 하고 싶어도 ground truth bounding box는 필요하다. 또, DETR 특성상 different masks가 align되도록 하는 heuristic이 요구되지 않는다.
A. Appendix
A.3
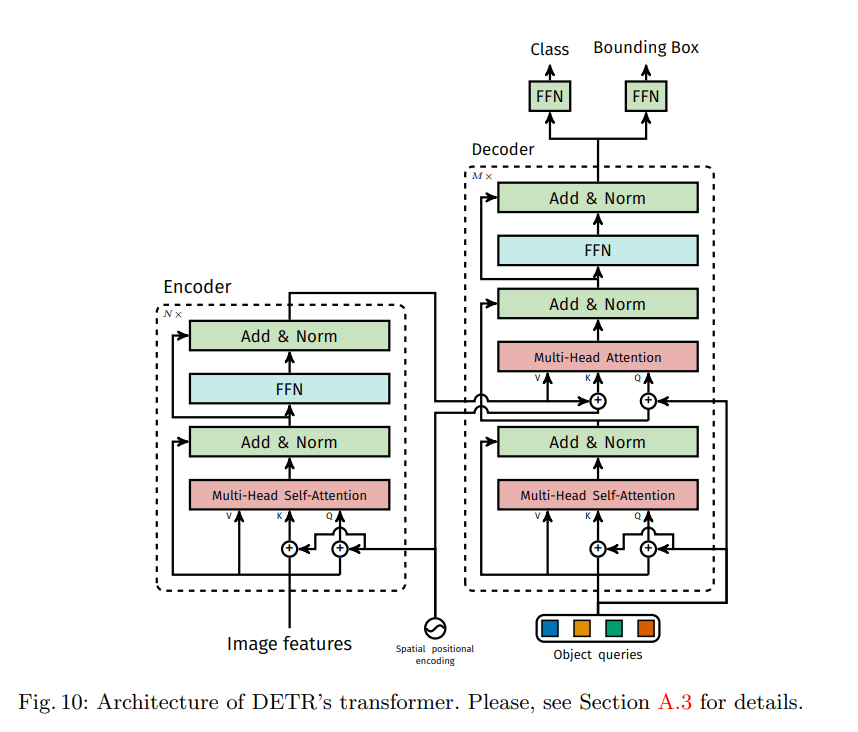
A.6
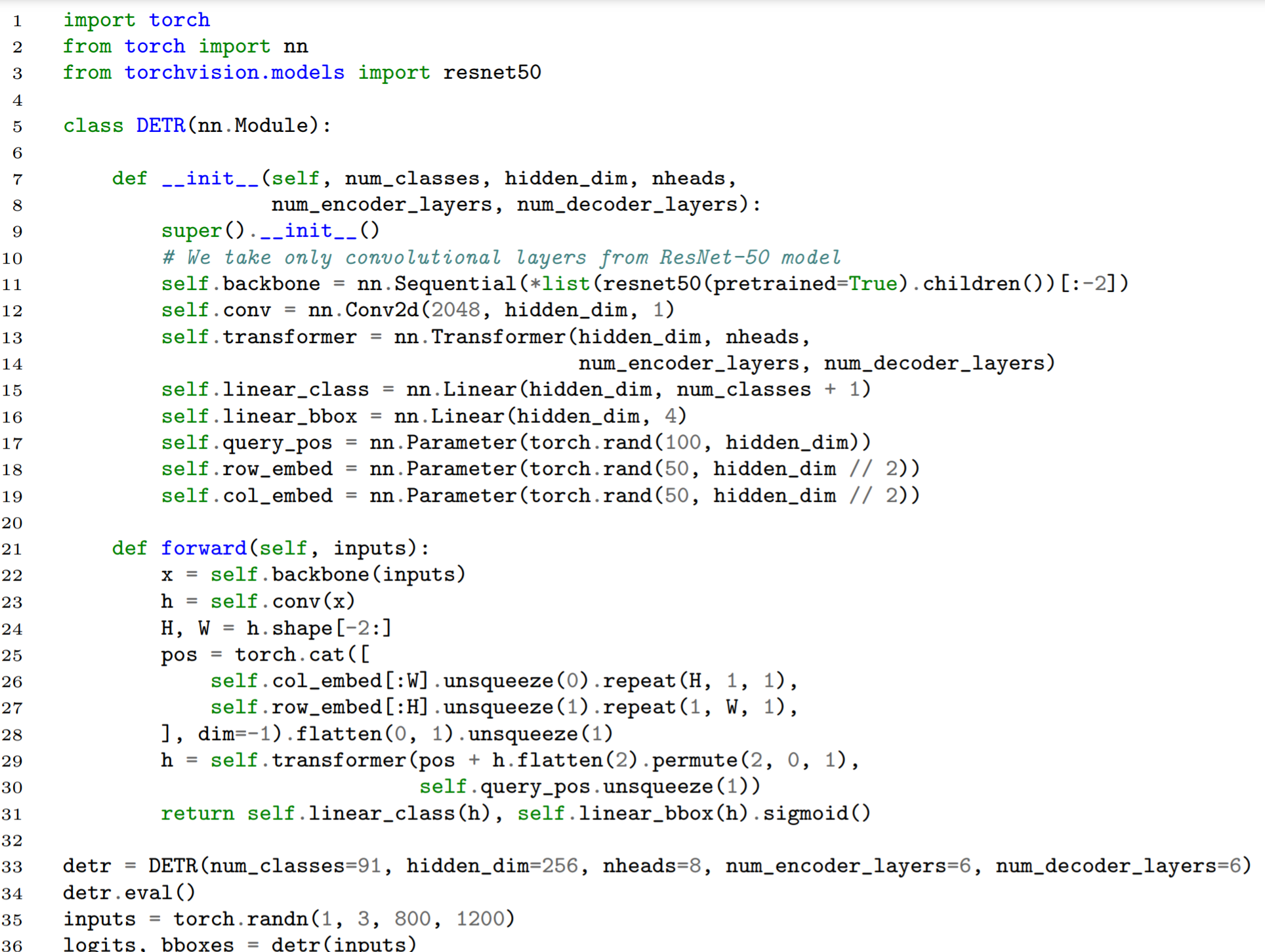
논문의 내용을 전부 구현한 소스코드가 아님에 유의하자. 예를 들어 positional encoding at attn., auxiliary loss 등이 구현되어 있지 않다.
참고 자료