Growing 3D Artefacts and Functional Machines with Neural Cellular Automata
이번에 리뷰해볼 논문은 NCA(Neural Cellular Automata)에 대한 것으로, Yannic이 Sebastian Risi와 인터뷰한 영상 The Future of AI is Self-Organizing and Self-Assembling (w/ Prof. Sebastian Risi) 에서 언급한 논문인데 재미있어 보여 가져왔다.
논문 내용을 간단히 요약하자면, 인접한 cell들끼리만 소통할 수 있는 환경에서 supervised manner로 여러 가지의 구조물을 만들 수 있는 것을 minecraft example을 통해 보여줬다. 여기에 더해 구조물 일부가 손상(damaged)되었을 때 자가수복하는 예시를 보여준다.
논문을 읽기 전 먼저 데모 영상을 보고 오는 것을 추천한다. Sebastian Risi가 올린 것으로, Minecraft Morphogenesis를 찍어 올렸다. 또한, 이 영상의 댓글에서 누군가 이게 어떻게 동작하는 것인지 굉장히 간단하고 명료하게 설명해 두었으니 읽어보는 편이 좋다.
Introduction
생명과학에서의 morphogensis에 대한 analogy을 이용해, 컴퓨터과학에서 쓰이는 Cellular Automata(CA) 개념을 개괄한다. 간단히 말해 각각의 cell이 인버한 cell들의 상태만에 의존해 업데이트를 반복하는 것을 Cellular Automata라고 하며, 이 때 update rule을 Neural Network를 이용해 수행하면 Neural Cellular Automata(NCA)라고 부른다.
이 논문에서 만드는 complex structure은 최대 3584 블럭, 50개 타입의 블럭을 다루니 참고하는 편이 좋다. 적지는 않지만, 그렇게 크지도 않다고 볼 수 있다.
논문의 저자는 이 연구의 main contribution이 다음과 같다고 말한다.
- 3D multi-class voxel에의 NCA 적용(extension)
- 움직이는 로봇(캐터필라)를 포함한 다양한 복잡도의 Minecraft structure을 cellular automation을 통해 generation
여기에 더해, NCA를 적용하는 데에 있어 범용적으로 쓸만한 loss function을 제안한다. (non-air IoU loss)
Related Works
아무래도 생소한 분야다보니 도대체 이게 언제부터 어떤 식으로 연구가 되어 온건지 적어두는 편이 좋겠다.
먼저, 다세포 생명체의 morphogenesis, irregular growth에 대한 developmental process를 모방하는 Cellular Automata는 1940년 제시되었다고 한다. (Neumann et al., 1966) 이후 CA가 생물학적 패턴을 이해하는 데나(Wolfram, 1984), 격자구조 기반 물리학 적 계를 모델링하는데나(Vichniac, 1984), 인공 생명체의 생성에 쓰일 수 있다(Langton, 1986)는 짐작(speculate)가 있었다.
NCA에 대해 소개하는데, 2002년 Li and Yeh가 여러 땅의 개발을 densely-connected neural network를 이용해 모델링하는데 NCA를 썼다. 이후 2017년부터 2D image과 3D structure generation에 NCA를 쓴 연구가 몇 있었다.
Growing Neural Cellular Automata
본 논문을 이해하는 데 있어 가장 도움이 될 것 같은 선행 연구로, Mordvintsev et al.(2020)의 Growing Neural Cellular Automata이 있다. NCA를 이용해 2D image를 생성했으며, 각각의 cell state을 size-16 state vector을 이용해 나타내었다. 이 state vector은 RGB value와 cell의 alive 여부, hidden channels을 포함하고 있었다.
각 cell에 대해 Sobel filter로 기울기를 구하고, 원래 cell state와 concatenation해, 이를 "perception vector"이라 부른다. 이러한 perception vector을 인공신경망에 넣어 update가 되도록 했고, 모든 cell에 대해 똑같은(shared) neural network를 이용함으로써 보편적인 update rule을 따르도록 했다.
loss는 보편적인 reconstruction loss를 썼고, catastrophic forgetting을 막기 위해 "sample pool"을 사용했다. 이것 말고는 각 cell의 독립적인 변화를 모방하기 위한 stochastic update나, alive-masking과 같은 기법을 사용했다.
유전 알고리즘을 공부해봤다면 알겠지만, 모두 그렇게 이상한 이야기는 아니다. 특히 stochastic update는 어떤 의미로는 굉장히 중요하다고 할 수 있다.
직접 체험해볼 수 있는 웹 데모로는 Growing Neural Cellular Automata (distill.pub) 가 있다.
Model Architecture
Mordvintsev et al.(2020)에서와 비슷한 방식을 쓰나, sobel filter 대신 learniable perception network를 이용한다.
kernel size 3, stride 1의 3d convolution을 이용한다. (output channels = cell state channels $\times$ 3)
1x1 convolution을 거쳐 업데이트되고, 업데이트는 50% 확률로 된다.(dropout) 또한 죽은 cell을 지우는 처리도 한다.
마인크래프트에는 여러 개의 블럭 종류가 있으므로 해결하는 문제는 기본적으로 multi-class classification이다. loss는 cross entropy loss를 써봤으나, ground truth에서 많이 존재하는 'air' 블럭이 우세하게 되는 문제가 있었다. 이를 해결하기 위해 non-air block에 대한 IoU loss를 추가한다.
Mordvintsev et al.(2020)에서와 같이 training에 사용된 step보다 더 오래 generation을 지속했을 때 시스템이 불안정해지는 문제가 있었고, Mordvintsev et al.(2020)에서와 비슷하게 sample pool of size 32를 사용해 해결한다. RL에서의 experience replay를 모방한 것이라 한다. 학습 step 역시 일정 범위에서 랜덤하게 선택한다.
Results
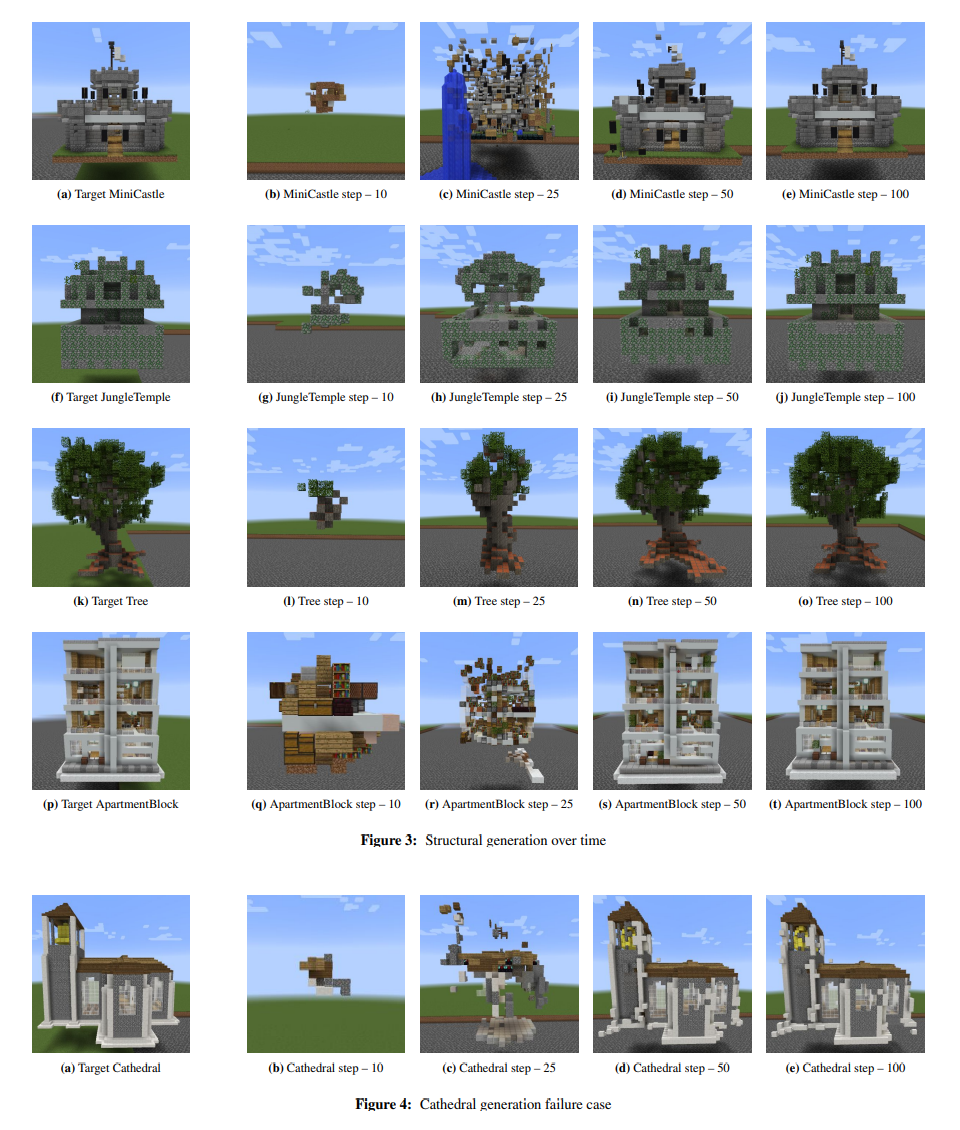
결과물을 보면, 완전하진 않지만 시험적이고 소규모인 모델 아키텍처를 감안했을 때 괜찮은 출력이 나온다.

실내도 잘 구현되어 있고, 사원의 화살 함정도 구현되었다고 하는데 근데 내가 직접 돌려볼 때는 화살 함정 작동 안되던데..?
아무튼, proof of concept 정도는 성공적으로 되는 것으로 보인다.
그리고, 내가 직접 실행해봤을 때, 나무의 경우 ground truth를 닮는 것처럼 보이나 중간이 비어있고 좀 뭔가 미묘하게 부실해 보이는(..) 나무가 생성된다. 나무의 밑둥도 빠진 블럭이 좀 있다. 사람이 마인크래프트에 나무를 만들 때는 중력을 받은 채로 구조적 평형을 이루는 현실의 나무를 본떠 만들었으나 AI는 그런 거 모르기 때문에 그런 디테일을 살리지 못한 것으로 보인다.

혼자 움직이는 캐터필라도 잘 만든다.
Regenerative Properties
일부를 훼손했을 때 자가수복하는 성질을 보인다. 내가 직접 확인해봤을 때도 어느정도 되는 걸 확인했었다. 다만 완전하지는 않고, 학습 과정에 따로 처리를 해주지 않으면 재생 능력이 떨어진다. (그럼에도 어느 정도 재생이 가능하긴 하다.)
Discussion and Future Work
흥미로운 이야기를 몇 하는데, 하나의 구조물을 학습하는 데 한 번의 학습이 필요하기 때문에 Ruiz et al. (2021)에서처럼 structural information을 encode한 autoencoder을 사용하는 방법을 제시한다.
또한 지도학습 대신 RL을 쓰는 방향성을 제시하고, 재미있게도 대형 레드스톤 컴퓨터를 학습하고 싶다고 말한다.