Pretrained Transformers as Universal Computation Engines
2021 3월 9일에 나온 Pretrained Transformers as Universal Computation Engines에 대한 간략한 리뷰를 다룬다. Yannic Kilcher과 이진원님의 영상을 보고 리뷰를 적어본다.
소개
이 논문은 pretrained Transformer가 처음부터 훈련하는 transformer보다 더 나은 성능을 보이고 수렴이 빨랐다는 내용이다. 특히, pretrain task는 다른 task가 아니라 NLP가 효과적이었다는 내용이다.
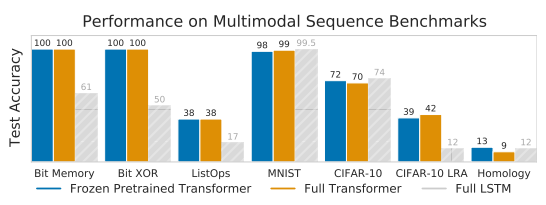
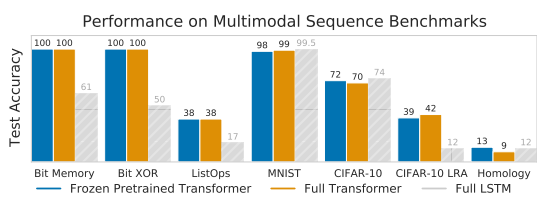
Frozen Pretrained Transformer가 Full Transformer보다 비슷하거나 일부 나은 성능을 보인다.

수렴 속도도 빠르다. XOR의 경우 40배나 빠르다. attention map을 보면 알겠지만 주목해야 하는 부분이 명확하게 존재해서 그런듯.
fine-tuning parameters
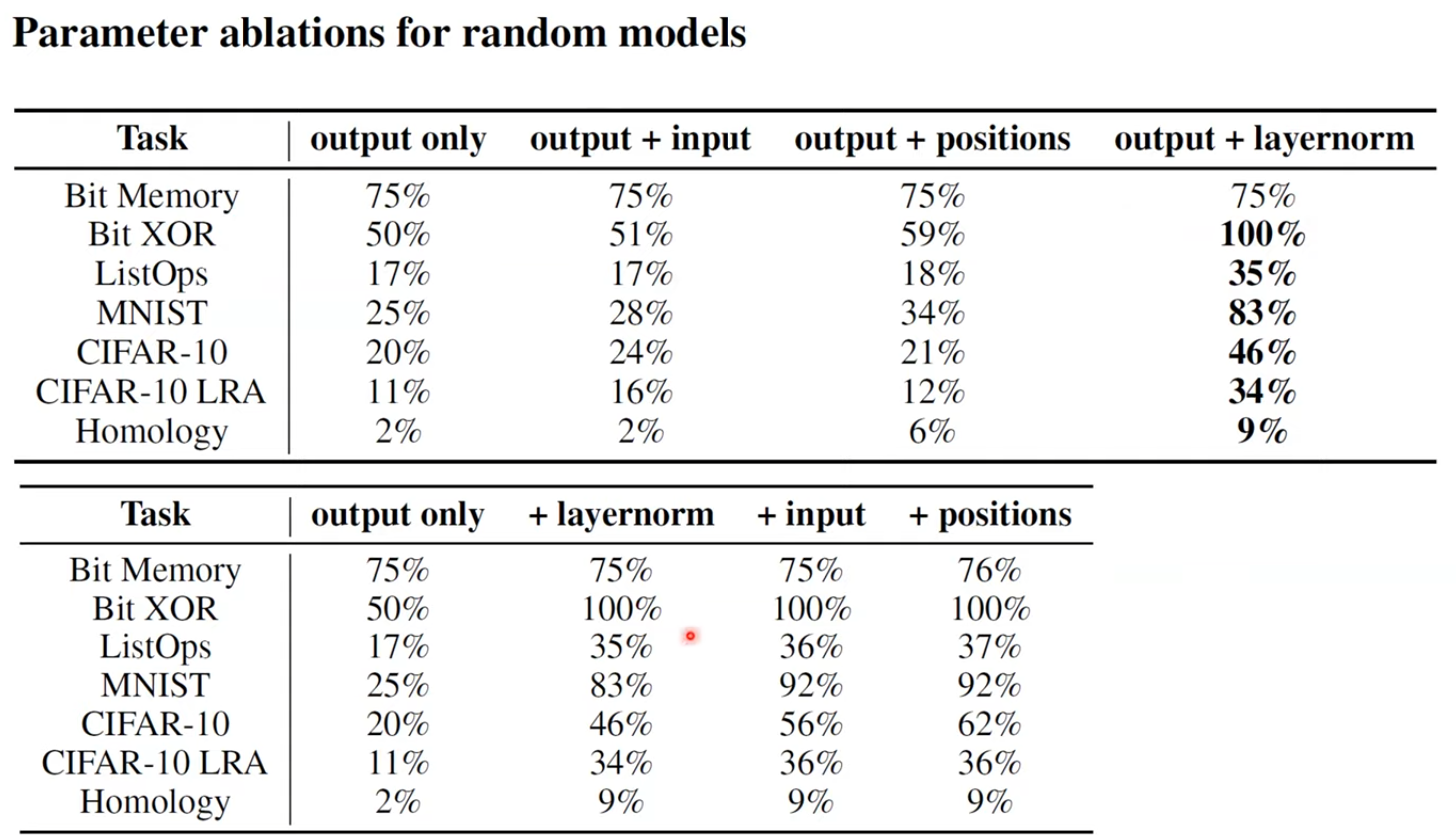
pretrained transformer을 fine-tuning할 때, output layer, input layer, positional embedding에 더해 transformer의 layer norm도 학습시켰음에 유의하자. Yannic Kilcher은 아마 그렇게 했을 때 결과가 잘 안 나와서 이렇게 layer norm도 freezing시키지 않았을 것이라 말하고 ablation에 해당 내용이 있다.
각 pre-train에 대한 fine-tuning 성능
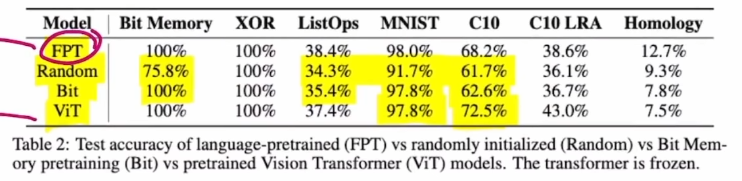
그리고 특히 NLP에 pretrain했을 때 성능이 좋다.
왜?
하지만 Yannic Kilcher도 말하듯, 이것은 NLP가 다른 task 중 “상위 호환 격”의 task여서 그런 것이 아니라 단순히 NLP가 더 “복잡한” task였기 때문에 그랬을 가능성이 있다. 간단히 말해, weight를 random initilization 했을 때 input에 대한 인공신경망의 output 함수는 상당히 flat할 것이다. 하지만 complex한 task인 NLP를 pre-train 시키면 봉우리가 여럿 생겨날 것이고 이는 향후 fine-tuning에 도움을 줄 가능성이 있다. Yannic Kilcher는 1번 옵션을 NLP 자체의 특성(grammar 등)으로 인해 NLP가 도움이 되었을 경우, 2번 옵션을 NLP가 복잡한 task여서 computational utility에 도움을 주어 fine-tuning에 도움이 되었을 경우 이렇게 2가지로 나눠 소개한다.
One ticket to win them all: generalizing lottery ticket initialization에서도 winning ticket을 transfer할때도 다른 데이터셋이 아니라 ImageNet과 같이 더 복잡한(단순히 데이터셋 크기가 큰 게 아니라 클래스 수가 많은) 데이터셋이 일반화 효과가 높았다고 한다. 이 내용과 내 추론이 비슷한 맥락이다.
이렇게 내가 가설을 세운 것에는 하나의 이유가 더 있는데, 저자가 fine-tuning을 하기로 한 task가 Memory, XOR, MNIST, Cifar-10등 너무 간단한 task 밖에 없었기 때문이다.(CIFAR-10의 경우 ConvMixer 기준 0.7M parameter로도 96%의 정확도가 나온다. 물론, 당연히, 이 논문에서 fine-tuning한 parameter 수가 더 적지만.) 이 정도는 NN의 output space에 봉우리가 여럿 생기는 것만으로 뒤에 달아둔 MLP가 학습이 편해질 가능성이 높을 것 같다.
특이하게(?) C10, C10 LRA의 경우 ViT pre-train이 성능이 더 좋은데 2D image input의 내재적인 특성이 attention layer에도 학습이 된 거라 볼 수 있다.
그나저나 하나 주목할 만한 건.. Random이 왜 이렇게 성능이 잘 나오지? 이유가 궁금하다. 그냥 attention layer이 존재하지 않는 것과 사실상 같은 효과를 내서 그런가? 그렇다면 random에다, attention을 아예 빼놓고 대조실험을 진행했으면 어땠을까 하는 아쉬움이 남는다.
Attention mask
masked attention을 사용했기에 행렬의 우측 상단이 0임에 유의하자.
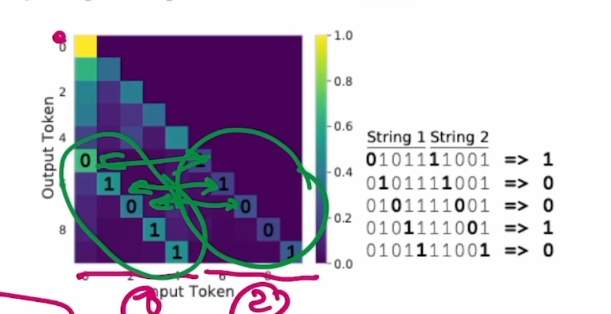
Attention Mask가 XOR test에 어떻게 나오는지 나타낸 것으로, element-wise하게 XOR 과정에 필요한 2비트만 attend가 잘 되는 것을 알 수 있다. attention의 weight는 유지해도 그 전에 존재하는 input layer의 parameter과 positional embeddings가 잘 tuning되면서 이렇게 변한 듯하다.
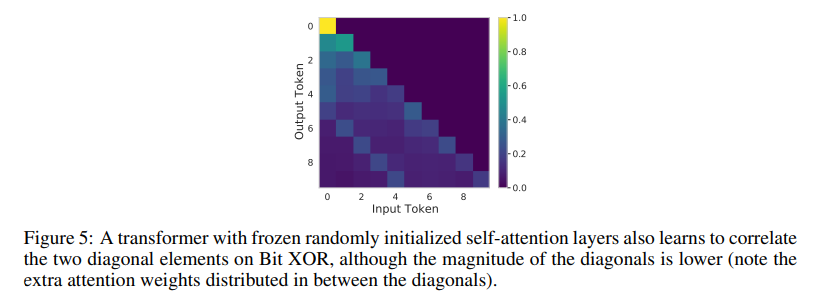
Frozen randomly initialized transformer은 위와 같이 정확하게 attend가 되지 않는다.
또 XOR과 memory 외에 다른 task에서는 사람이 해석할 수 있는 attention map이 나오지 않았다고 한다.
pre-train transformer의 통계치 가져다 쓰기
중간에 꽤나 흥미로운 내용이 있는데, pre-train한 Transformer의 layer별 parameter의 평균과 표준편차를 가져다 그 통계치를 기반으로 initialization해서 MNIST, CIFAR-10 등 task를 학습시키는 것이다. 일부 지표에서는 기초부터 학습해 나간 Default보다 Statistic을 가져다 학습한 쪽(Statistics Only)가 나았으나 C10-LRA에서는 오히려 Statistics Only가 Default보다 낮은 성능을 보이기도 한다.
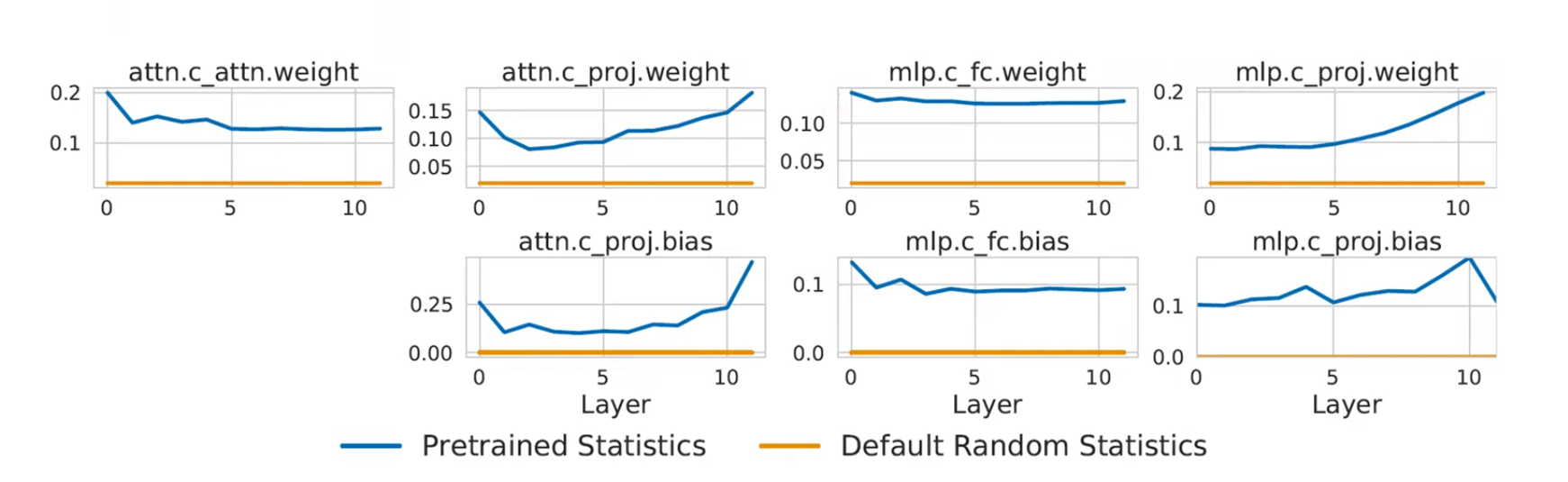
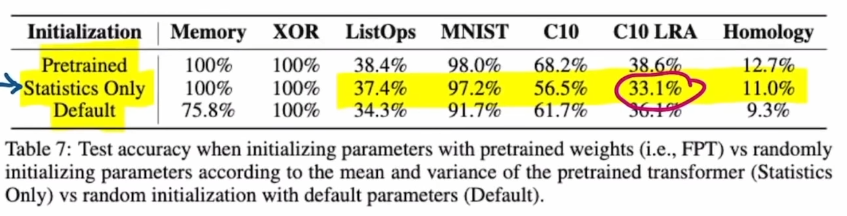
다만 Yannic Kilcher의 의견과 비슷하게, 실험이 너무 rough했으며 적절한 transformer의 weight initialization, 또는 pre-train된 모델에서 적당한 값을 가져오는 것이 학습에 도움을 줄 가능성은 충분히 있다고 본다. 예를 들어 영향력이 높은 파라미터만을 가져와서 그대로 적용한 후에 학습한다면?
또 2-factor, 다시 말해 오직 mean과 variance만을 가져다 사용한 것은 상당히 아쉬운 부분이다. 경제학에서도 2-factor 모델은 실제 현상과 안 맞다고 왜도, 첨도 등의 factor을 점차 추가해 나가지 않는가. 그러고 보니 훈련이 완료된 파라미터가 애초에 정규분포를 따르던가? 간단히 다른 논문의 Figure만 봐서 확인해 보니 역시나도 정규분포처럼은 안 생겼다.
또 Yannic Kilcher은 나아가 비슷한 맥락에서 너무나도 어려운 task를 인위적으로 합성해 pre-train 시키면 fine-tuning에 도움이 되는 모델이 나올 수도 있다고 언급하는데 한번 확인해볼만 하다는 생각이 든다.
Transformer parameter을 freezing시키지 않으면?
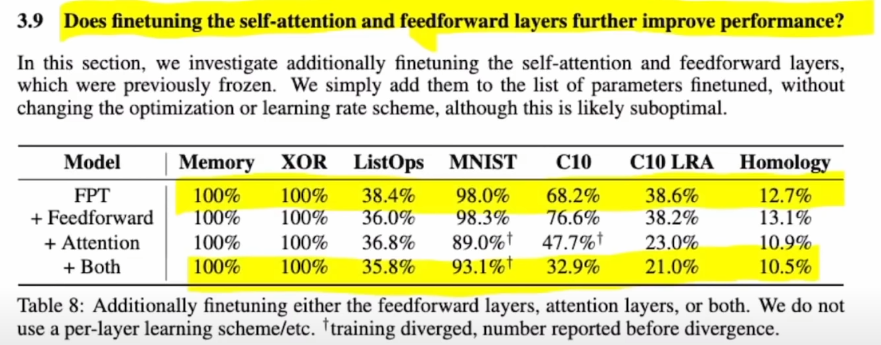
그리고 모델 맨 뒤에 붙는 MLP뿐만 아니라 Transformer도 학습시켰을 때 어떻게 될지도 실험하는데 어.. 예상대로 성능이 내려간다 ㅋㅋㅋ 그야 fine-tuning하는 task가 너무 단순하니 overfitting이 되는 것으로 보인다.
뭐가 중요하나?

layer norm parameter가 가장 중요하다고 언급한다.
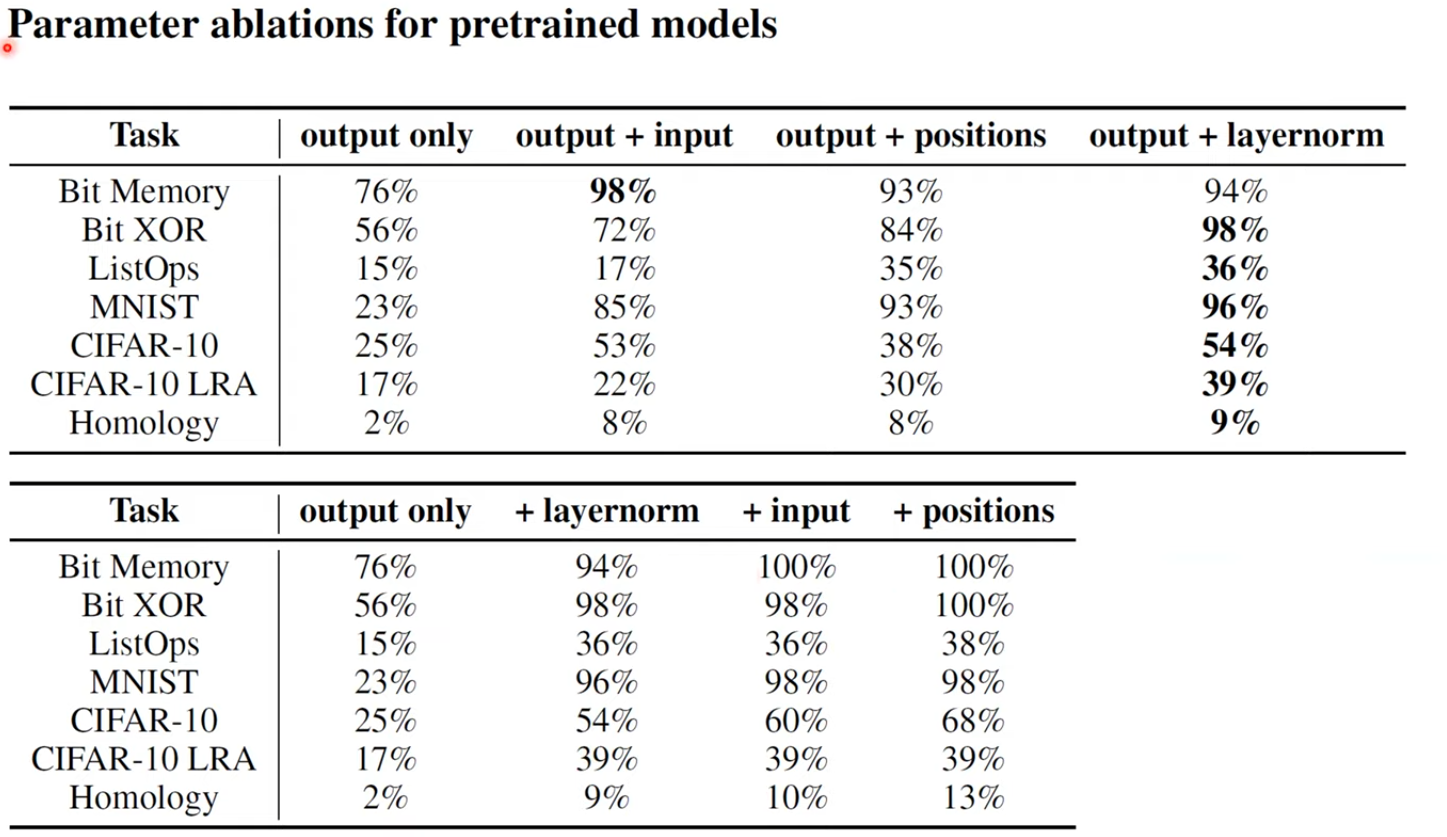
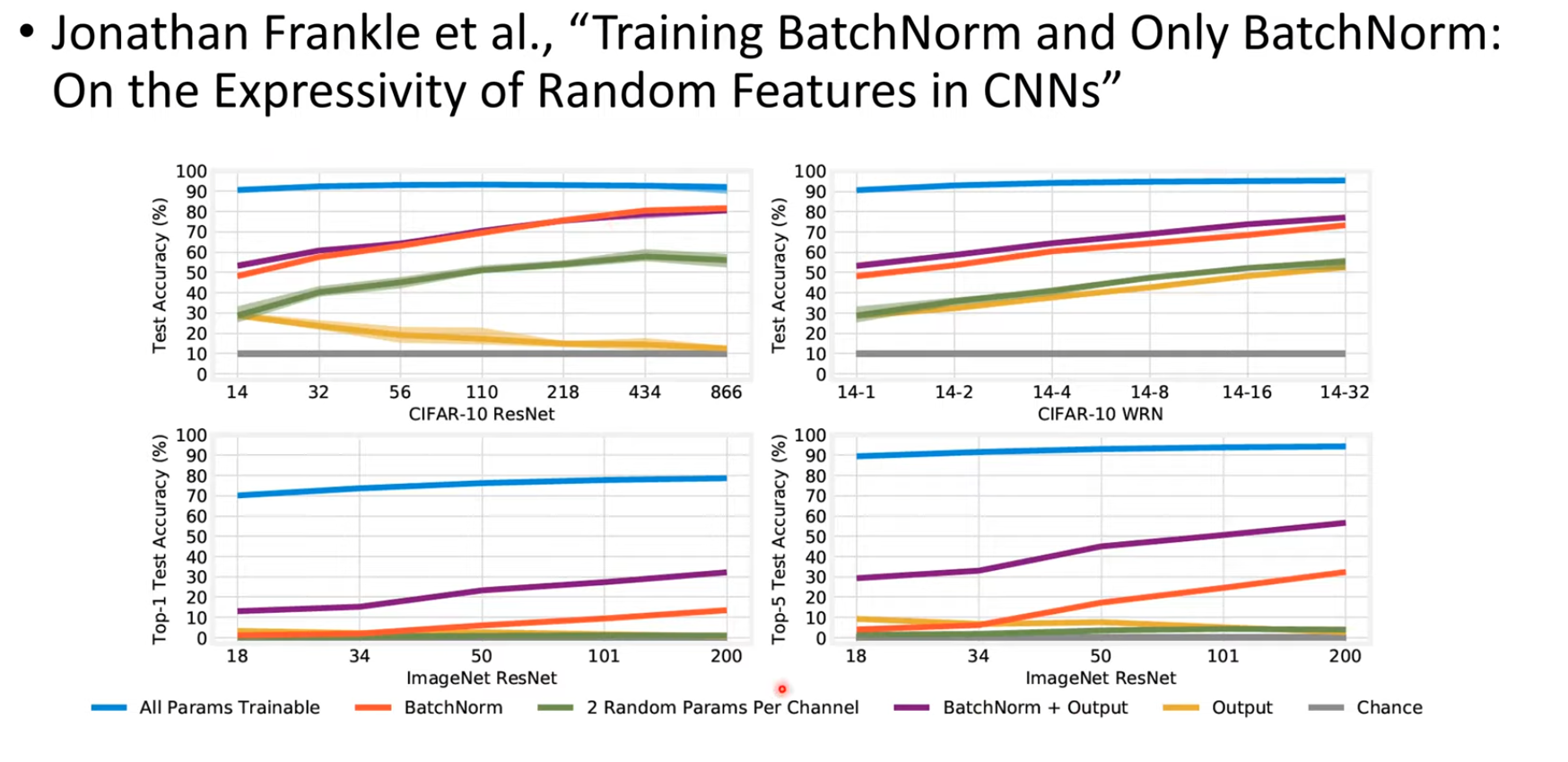
그리고 이진원님의 PR-304에서 굉장히 흥미로운 논문을 추가로 제시하는데, CNN에서 batch norm만을 학습시켰더니(Convolution의 weight는 freeze) 성능이 굉장히 잘 나오더라는 것이다.
output layer만 fine-tuning하면?
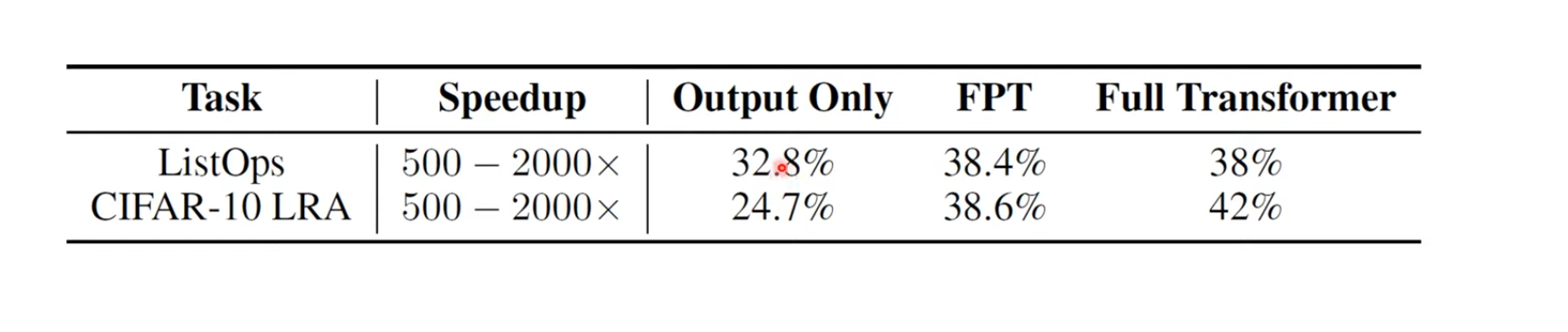
수렴 속도는 2000배까지 엄청나게 빨라지나 성능이 하락한다. 그리고 overfitting을 한다고 한다.
결론
전반적으로 rough한 논문이라는 생각이 들었고, 내용에 대해서는 뭔가 이상하다는 내용도 있긴 했지만 그것과 별개로 이미 학습된 모델의 weight를 적당히 가져오면 심지어 서로 다른 modality의 task의 fine-tuning에도 도움이 될 수 있다는 굉장히 흥미로운 내용을 다룬 논문이며 앞으로의 활용 가능성이 엿보인다. 아쉬운 점은 좀 있어도 pre-trained된 transformer가 universal computational engine이 될 수 있는지 탐구해본 건 굉장히 좋은 시도가 아니었나 싶다.
또한 convolution, attention 같은 연산의 weight을 학습시키지 않고 norm layer만 학습시켜도 (생각보다) 성능이 굉장히 잘 나온다는 굉장히 흥미로운 insight까지 얻어갈 수 있었다. 별 생각 없이 논문 읽어볼 생각도 없이 심심한데 논문 리뷰 영상이나 볼까 열어본 논문인데, 생각보다 굉장히 도움이 되었다.
참고 자료
PR-304: Pretrained Transformers As Universal Computation Engines
Pretrained Transformers as Universal Computation Engines (Machine Learning Research Paper Explained)