CoAtNet: Marrying Convolution and Attention for All Data Sizes
요약
이 논문에서는 convolution과 relative attention(의 변형)를 적절히 섞고 JFT에서 pre-training해 ImageNet-1K에서 90.88%로 SOTA를 차지하고 있는 CoAtNet(코트넷)에 대해 소개한다.
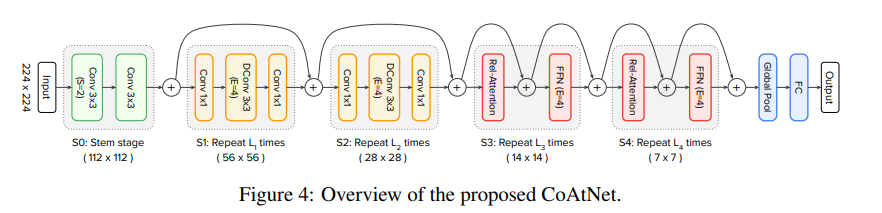
2. Model
2.1 Merging Convolution and Self-Attention
이 논문에서는 depthwise convolution을 이용한 MBConv와 Transformer을 합치는 방법을 고안한다. MBConv를 고른 이유는 Transformer의 FFN에서도 channel 개수가 늘어났다 줄어드는 inverted bottleneck 구조를 사용하기 때문이다. (4x 늘어났다 4x 줄어든다.)
익히 알듯 Convolution은 Translation Equivariance를 가지고 있는 것이 장점이 되고, Self-Attention은 Input-adaptive weighting이 되고 global receptive field가 장점이다. 논문에서는 둘을 합쳐본 아래와 같은 수식 2개를 제시한다.
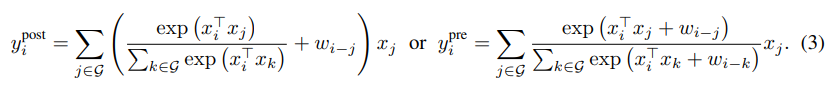
흥미롭게도 $y^{pre}_i$는 relative self-attention의 변형에 대응된다. 또 수식의 $w_{i-j}$는 파라미터 개수를 줄이고 계산 비용을 줄이기 위해 스칼라로 쓴다고 한다. 이 논문에서는 위의 둘 중 후자인 pre-normalization relative attention varient를 사용한다고 한다.
2. Vertical Layout Design
self-attention의 time complexity는 $O(N^2)$이므로 ImageNet의 대형 이미지(224*224)에 그대로 쓸 수는 없다. 따라서 1) 다운샘플링 후 attention 2) local attention 사용 3) linear attention 사용 이 3 가지 방법이 있는데, 이 중 1)을 채택한다. 3)의 경우 간단히 해봤지만 좋은 결과가 나오지 않았고 2)의 경우 non-trivial shape formatting operation의 특성상 TPU에서 매우 느리게 돌아가서 그렇다고 한다.
다운샘플링은 크게 2가지 방법으로 시행한다.
-
ViT에서처럼 16*16 patch로 나눈다.
이렇게 ViT Steam이 쓰이면 이후 $L$개의 Transformer block을 바로 이어주고, 이를 $ViT_{REL}$로 표기한다.
-
multi-stage ConvNet으로 downsampling한다.
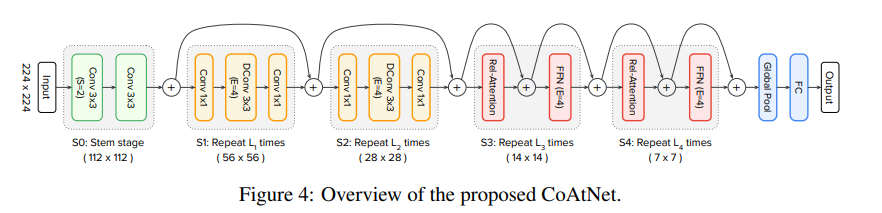
5개의 단계로 이루어진 ConvNet을 사용한다. 각각을 $S0, S1, S2, S3, S4$로 표기한다. 단계를 거치며 점점 해상도를 줄여나간다. 매 단계별 크기를 2x 줄이며 채널은 늘린다. 더 자세한 내용은 Appendix A.1과 후술할 내용 참조.
S0은 간단한 2-layer convolutional Stem이고, S1는 squeeze-excitation 포함한 MBConv이다. 이후 Transformer을 넣느냐 Convolution을 넣느냐에 따라 CCCC, CCCT, CCTT, CTTT를 후보군으로 두고 설정하고 일반화 능력, model capacity, transferability에 대해 test를 진행하고 CCTT를 최종 선정한다.
CCTT까지 선정하는 과정에서, $ViT_{REL}$의 일반화 능력은 예상대로 다른 모델에 비해 매우 떨어졌으며 T가 많다고 model capacity가 무작정 올라가는 건 아니었다.
3. Related Work
-
Convolutional network building blocks
고전적으로 ResNet block은 large-scale ConvNet에 자주 쓰여왔다. 그에 반해 depthwise convolution은 낮은 계산 비용과 작은 파라미터 사이즈로 인해 mobile platform에서 자주 쓰여왔다. 최근 연구는 depthwise convolution을 사용하는 improved inverted residual bottleneck(MBConv)이 높은 정확도와 나은 효율성을 모두 달성할 수 있다는 것을 보여줬다. 또한 MBConv와 Transformer block에는 inverted bottleneck이라는 공통점이 있으므로 이 논문에서는 MBConv를 convolution building block으로 사용했다.
-
Self-attention and Transformers
ViT가 transformer을 이용해 vision task를 수행했지만 JFT의 대규모 데이터셋 없이는 성능이 부족했다. DeiT 을 언급할 것 같았는데 이 논문에서는 언급하지 않은듯..?
-
Relative attention
쉽게 말해 공간적으로 가까울수록 더 높은 흥분도를 주는 attention 연산에 대한 이야기이다. 나도 이쪽 논문은 더 읽어봐야 한다.
-
Combining convolution and self-attention
생략. 나중에 수정
4.1 Experiment Setting

-
CoAtNet model family
Table 3 참고.
S1~S4까지 channel은 항상 2배씩 늘렸고, S0 channel 은 S1 이하로 유지했다.
-
Evaluation Protocol
ImageNet-1K(1.28M images), ImageNet-21K(12.7M image), JFT(300M image)를 이용해 pre-train 후에(resolution 224 그리고 300, 90, 14 epoch) 30 epoch 동안 ImageNet-1K로 finetuning했다.
-
Data Augmentation & Regularization
RandAugment와 MixUp만을 data augmentation에 고려했고 stachstic depth(transformer의 수렴을 돕는다는 말을 DeiT 논문에서 봤었다), label smoothing, weight decay를 모델을 정규화하기위해 고려했다.
pre-training에서 어떠한 종류의 augmentation을 하지 않다가 fine-tuning 때 하는 것은 보통 performance를 손상시킨다는 흥미로운 이야기도 있었다. 데이터 분포 변화와 관련이 있는 것으로 추측한다고 한다.
4.2 Main Results
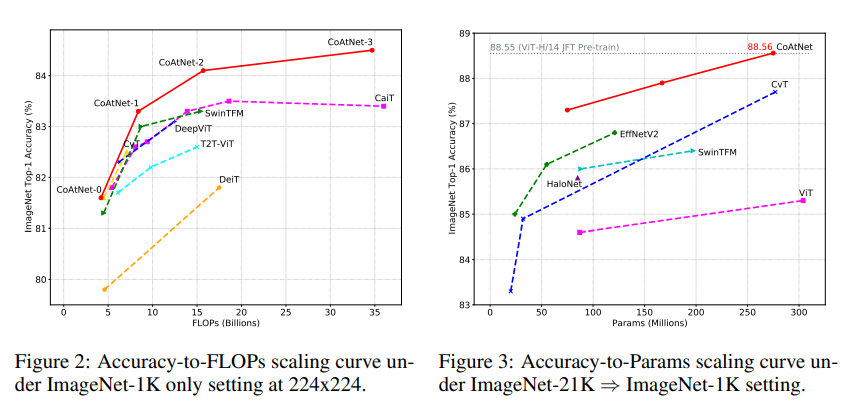
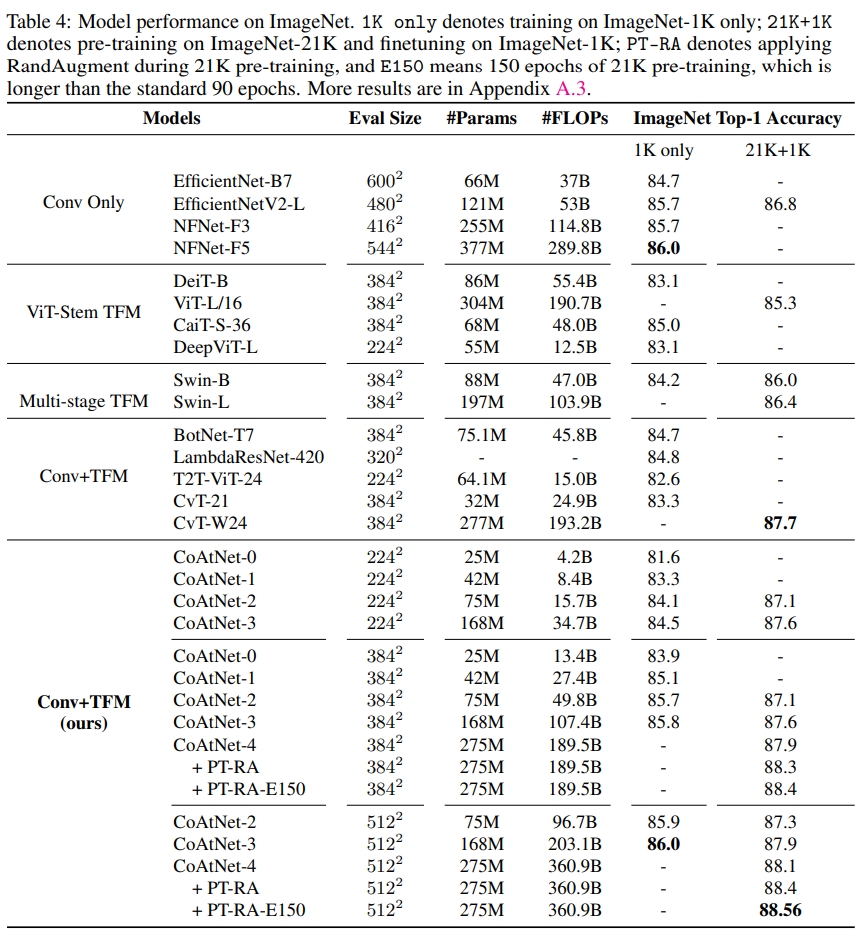
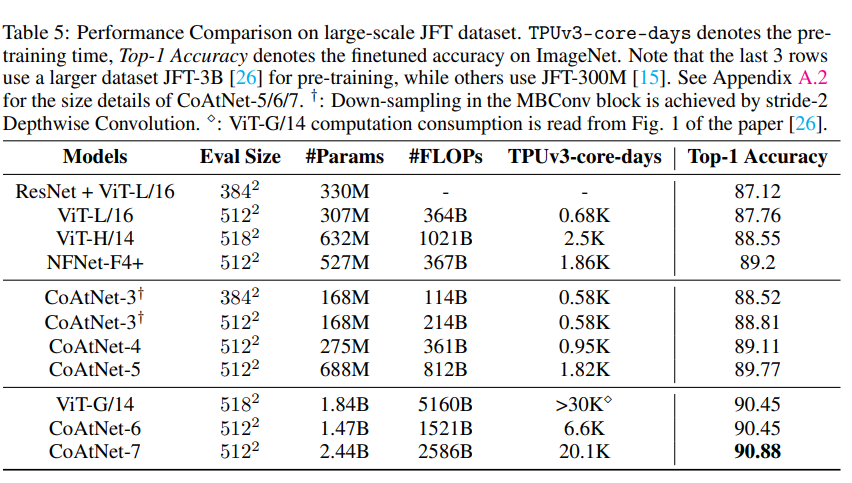
JFT로 pre-traning하면 일단 Top-1 Accuracy는 1위이다. 근데 이걸 SOTA라고 할 수.. 있나?
4.3 Ablation Studied
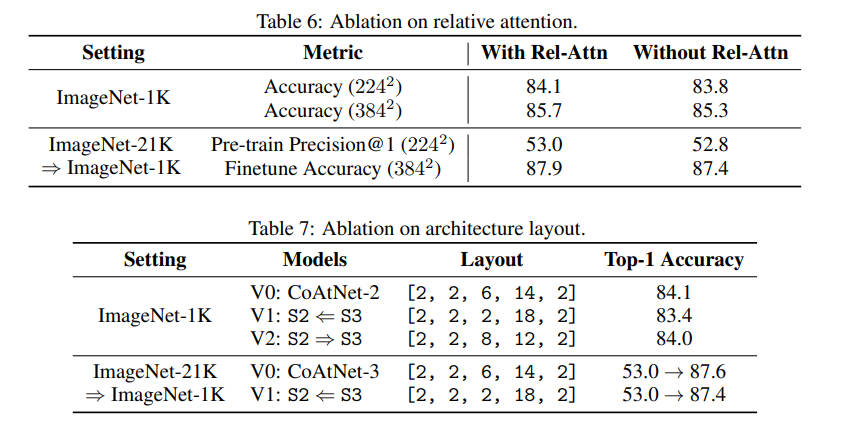
Relative attention을 attention 대신 썼을 때 accuracy가 올라간 것을 보여준다.