Training data-efficient image transformers & distillation through attention
영상을 통해 30분동안 학습하고 싶다면 위 영상을 추천한다.



Abstract
최근 attention에만 기반하여 image classification을 하는 모델(ViT)가 제시되었다. 그러나 이는 막대한 양의 pre-train data를 필요로 하며, 이는 이 모델의 채택을 어렵게 한다.
본 논문에서는 ImageNet만을 사용하여 훈련하는 transformer 기반 모델을 제시하며, 우리는 1대의 컴퓨터에서 3일보다 적게 훈련하여 외부 데이터 없이 top-1 accuracy 83.1%를 ImageNet에서 달성한다.
더 자세히는, transformer에 대해 teacher-student strategy (knowledge distillation)을 제시한다. 이는 distillation token을 통해 student가 teacher(especially convnet)을 따라 학습하도록 만드는 것이다. 우리는 ImageNet과 transfer task에 대해서 모두 convnet과 경쟁력이 있는 결과를 내는 것을 확인했다.
1. Introduction
ViT에서 convolution 없이 transformer만을 사용해 이미지 분류를 하는 모델을 제시했지만, 이 논문에서 "do not generalize well when trained on insufficient amounts of data"라고 서술했듯 ViT는 대규모의 pre-train 데이터셋을 필요로 한다.
우리는 ViT의 구조를 기반으로 하였고 timm library의 improvement를 포함하였다. 기존의 distillation 방식을 대체한, token-based의 knowledge distillation 방식을 제시했으며, 이 논문에서 제시한 모델을 Data-efficient image Transformer(DeiT)이라 부른다.
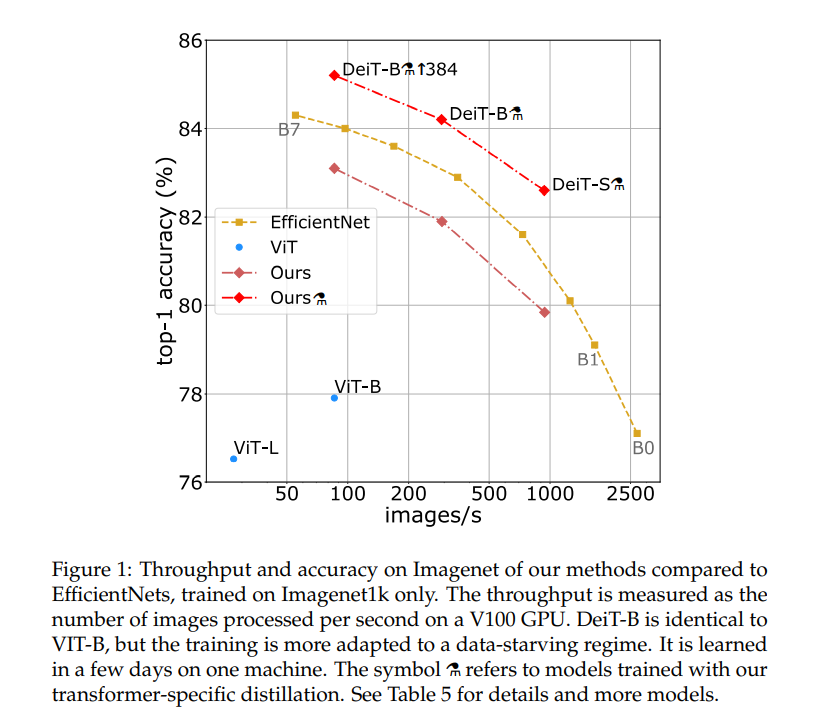
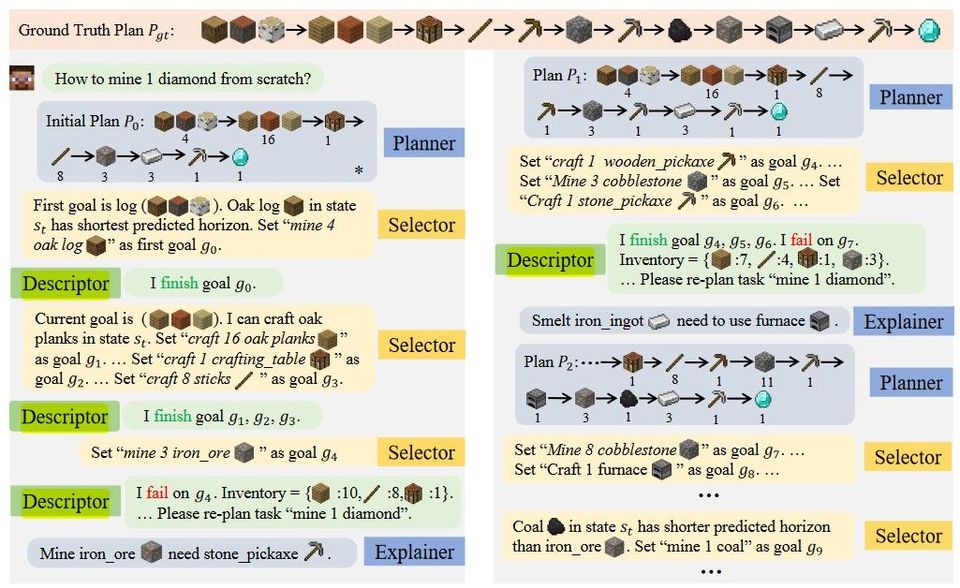
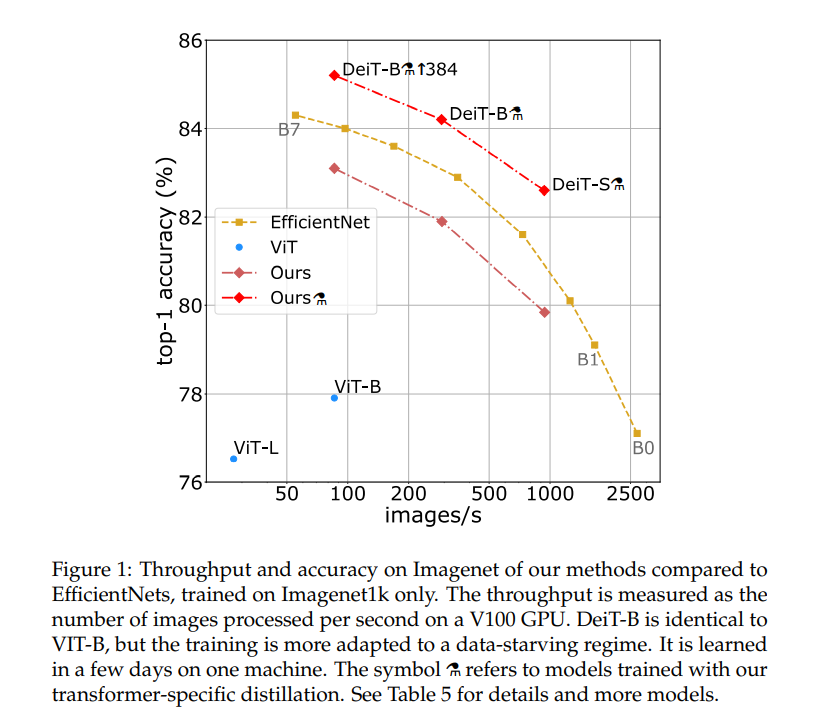
Figure 1은 accuracy-speed trade-off를 그래프로 보여준 것으로, 여기에서 ViT는 ImageNet만을 이용해 학습한 ViT이다. 속도와 정확도 면에서 모두 준수함을 알 수 있다.
본 논문에서 거둔 성과는 다음과 같다:
- 외부 데이터 없이 ImageNet만으로 convolutional layer 없는 모델이 SOTA와 경쟁력이 있는 결과를 냈다.
- distillation token에 기반한 새로운 distillation procedure을 소개하였다. distillation token은 clas token과 같은 역할을 하지만, teacher이 예측한 label을 목표로 학습한다는 점만 다르다. 두 토큰은 attention을 통해 transformer에서 상호작용하며, 이러한 전략은 vanilla distillation을 상당히 상회한다.
- 흥미롭게도, another transformer보다 convnet에서 더 많이 배운다. (inductive bias)
- 다른 downstream task에 transfer시킬 때도 경쟁력이 있다.
2. Related work + 3. Vision Transformer: overview
Related work에서는 image classification, the transformer architecture, knowledge distillation(KD)를 소개한다.
Vision Transformer에 대해서는 AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 로 설명을 대체한다. ViT 논문에 대한 설명을 읽고 오는 게 전체 내용을 이해하기 좋을 것이다.
4. Distillation through attention
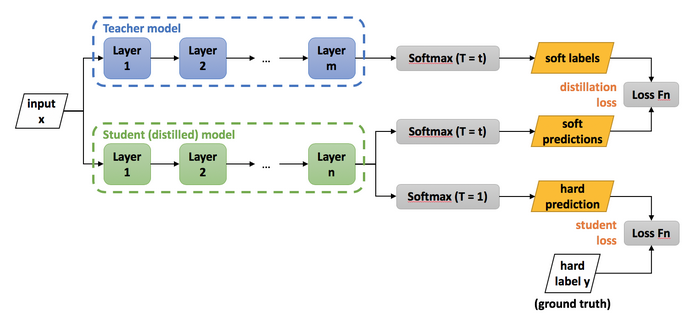
Knowledge Distillation이란 teacher과 student의 개념을 도입하여, student가 최소한 teacher model과 비슷한 성능을 낼 수 있도록 teacher의 지식을 student에게 전달하려는 기법이다.
크게 Soft distillation과 Hard distillation이 있다.
- Soft Distillation
softmax 후, argmax 하기 전의 값(soft prediction)이 student model과 teacher model에서 같도록 한다.
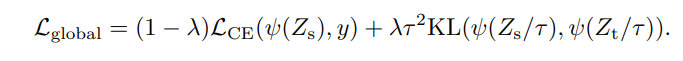
우변의 첫번째 항은 ground truth에 대한 cross entropy, 두번째 항은 KL divergence(Kullback-Leibler divergence)로서 두 확률분포의 차이를 나타내는 지표이다.
\[D_{KL}(P \|Q)=\sum_{x \in X}P(x)\log(\frac{P(x)}{Q(x)})\]
수식을 보면 shannon entropy와 수식이 굉장히 비슷하다는 것을 알 수 있는데, KL divergence의 의미는 Q에 대한 P의 상대적인 엔트로피이다. almost everywhere에서 \(P=Q\)이면 KL divergence가 0이 된다
- Hard Distillation
softmax 후, argmax 한 후의 값(hard prediction)을 기반으로 loss를 계산한다.
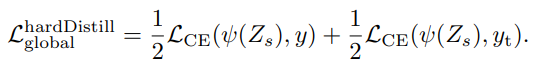
label smoothing도 사용 가능하며, 논문의 저자는 \(\epsilon=0.1\)을 사용하였다. 또한 수식은 \(1/2\)로 가중치를 뒀는데 그것도 소스코드에는 \(\alpha\)로 설정하였던 걸로 기억한다.
4.1 Distillation Token
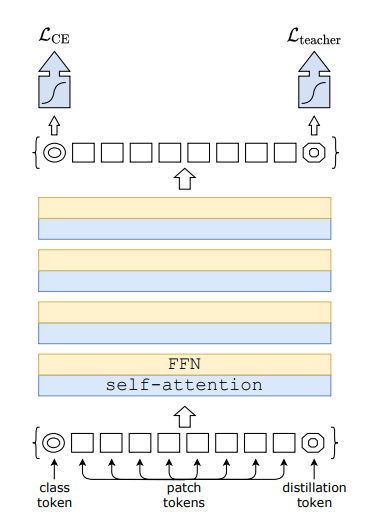
distillation token이라는 것을 DeiT에서는 도입한다. 이것은 class token과 똑같은 역할을 하는데, ground truth를 진짜 ground truth 대신 teacher model의 prediction 값을 사용한다는 점만 다르다.
다만 class token과 distillation token의 코사인 유사도는 0.06으로 학습되고, forward pass 1번 후에는 0.93까지 올라가는데, 둘이 정확히 같다면 1까지 올라가야 하는데도 0.93까지만 올라갔다고 한다. 이는 class token과 distillation token이 정확히 똑같도록 학습이 되지 않는다는 것을 뜻한다.
대조연구를 하기 위해 distilliation token 자리에 class token과 똑같이 ground truth를 기반으로 학습하는 token을 넣어봤는데, 이때는 cosine similarity가 0.999가 나왔다고 한다.
논문에서는 이렇게 cosine similarity가 1보다 작은 이유를, 예를 들어 고양이가 구석에 있는 이미지에서, data augmentation을 하려고 crop을 했는데, 고양이가 없는 부분이 crop되면, teacher model의 예측값은 고양이가 아니고 ground truth는 고양이일 때가 있을 것이라고 설명한다.
5. Experiments
5.1 Transformer models
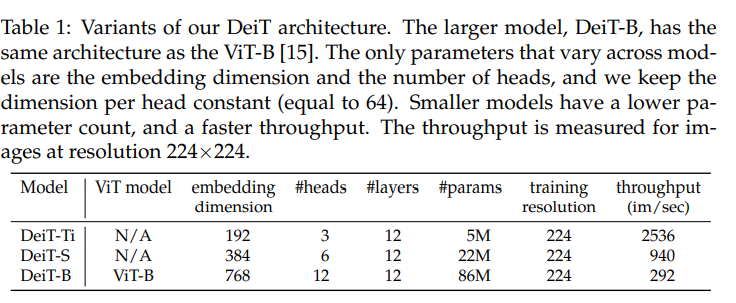
Table 1은 embedding dimension, number of heads만을 조정해 만든 여러 DeiT의 parameter을 나타낸다.
5.2 Distillation
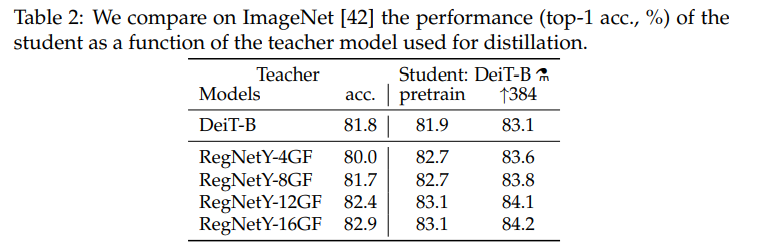
Table2는 각 Teacher(좌측)에 따른 Student(우측)의 accuracy를 나타낸다. (ImageNet, top-1 acc)
DeiT-B가 Teacher일 때는 성능이 teacher과 거의 같았지만, RegNet이 teacher일 때는 오히려 teacher의 성능을 뛰어넘는 모습을 보여준다. 이는 CNN(RegNet)의 inductive bias가 DeiT에 전달되어 그런 것이라 해석할 수 있다.
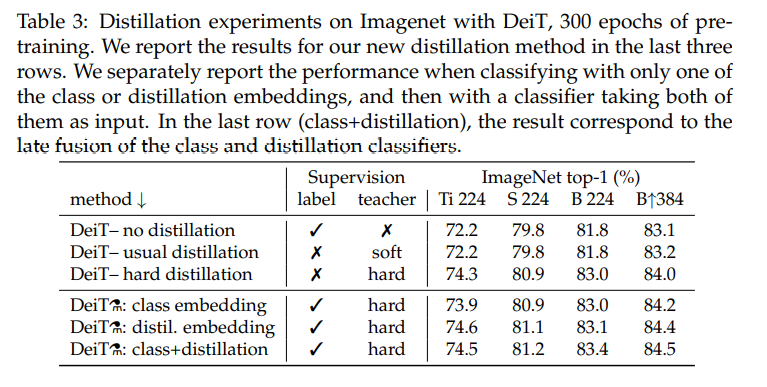
Table 3의 위쪽 3행은 class token만 사용했을 때, 아래쪽 3행은 class token과 distillation token을 동시에 사용했을 때를 뜻한다. 또한 아래 3행은 prediction을 class embedding만 사용했을 때, distillation embedding만 사용했을 때, 둘의 평균값을 사용했을 때를 순서대로 뜻한다. DeiT 구현을 보면, forward함수에서 (x + x_dist / 2), 즉 둘의 평균값을 반환하는 것으로 구현해놓은 것을 확인할 수 있다.
위쪽 3행을 보면, class token만을 이용해 distillation을 했을 때는 hard distillation이 큰 성능 향상을 이끌었으며, 아래쪽 3행을 보면 이 논문에서 제시한 distillation token을 썼을 때 추가적인 성능의 향상이 있었다고 주장한다.
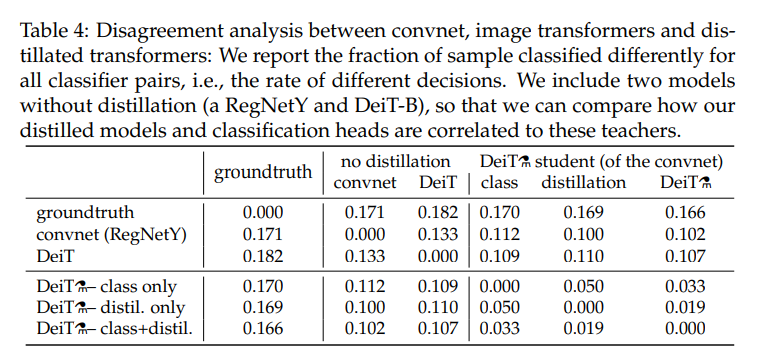
과연 정말로 convnet의 inductive bias를 DeiT가 배워갔을까?를 논증하기 위해, Table 4를 제시한다.
teacher 없는 DeiT와 convnet과의 disagreement 정도는 0.133이며, distillation token을 도입했을 때는 이것이 더 작아진다. 또한, DeiT⚗(아래 3행)의 경우 distillation token만으로, 혹은 class+distil.으로 prediction을 했을 때는 convnet과의 disagreement 정도가 더 작았으며 이는 예측했던 바라고 논문에서는 주장한다.
5.3 Efficiency vs accuracy: a comparative study with convnets
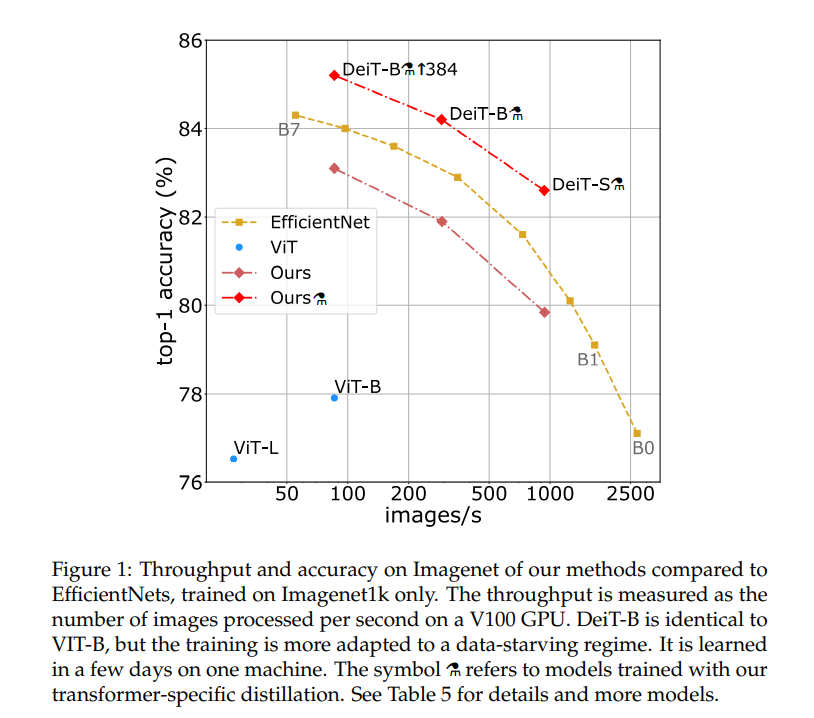
Figure 1에서, DeiT는 ViT에서 distillation을 적용하여 6.3%의 improvement를 이루었지만 EffcientNet의 약간 밑이다. 그러나 RegNetY를 distillation token을 이용해 학습하면(⚗) EfficientNet을 1%가량 뛰어넘는다.
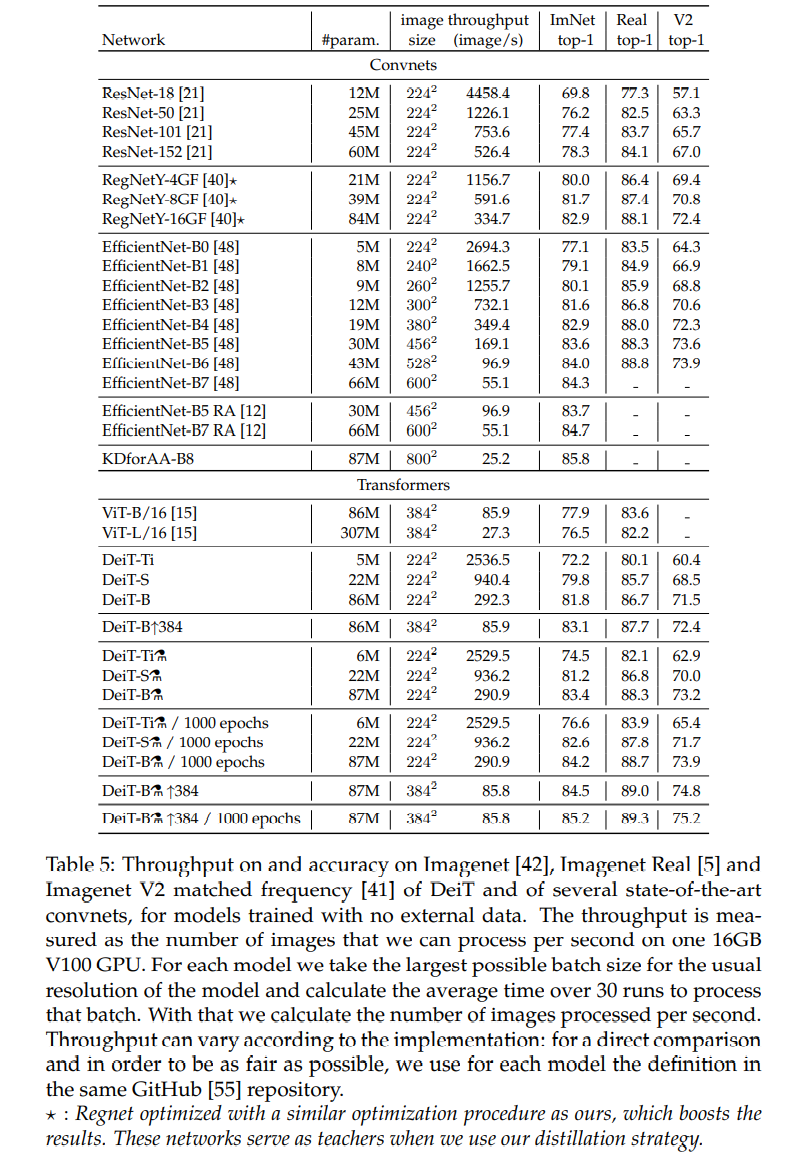
Table 5를 보자. DeiT-S⚗과 EffcientNet-B4 정도를 비교하자. Parameter은 22M 대 19M으로 비슷하고, 정확도도 82.6%대 82.9%로 비슷하다. 하지만 inference는 image/s가 936.2대 349.4로, DeiT가 더 빠른 것을 확인할 수 있다.
5.4 Transfer learning: Performance on downstream tasks
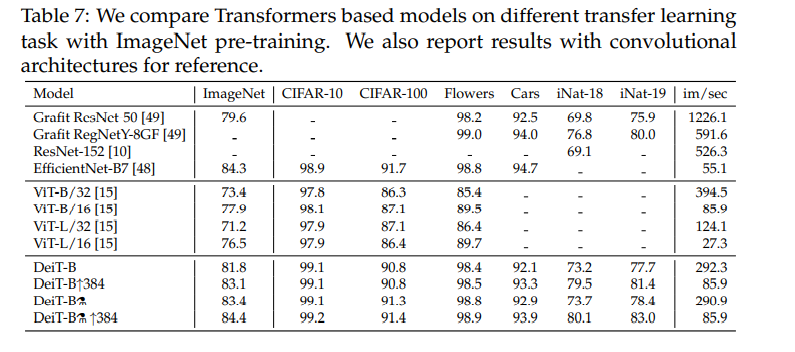
Table 7을 참고하자. Transfer learning도 매우 잘 되는 것을 확인할 수 있다.
6. Training details & ablation
특기할 만한 점
-
Transformers가 initilization에 대해 상대적으로 민감하다. "The effect of initilization and architecture"(Hannin and Rolnick, et al.) 참고했다고 함.
-
Data Augmentation
transformer은 기본적으로 많은 데이터를 필요로 하며, 거의 모든 data augmentation method가 useful했다. 데이터가 많을수록 좋다.
-
Regularization & Optimizers
transformer이 setting of optimization hyper-parameter에 민감하다고 한다.
특히 깊은 transformer의 수렴에 도움을 주는 stochastic depth을 사용했다고 한다. 그 외에 Mixup, CutMix, Repeated Augmentation 등을 사용했다고 하며 특히 Repeated Augmentation에 대해서는 provides a significant boost in performance and is one of the key ingredients of our proposed training procedure이라고 언급할 정도다. 한번 관련 논문을 읽어봐야겠다. RA가 처음 제시된 논문은 Multigrain(설명)으로 추정된다.
-
Batch Augmentation
하나의 배치에 하나의 이미지에서 나온 augmented images가 있는 게 성능이 좋고 generlization of the network를 향상시키더라.
-
Repeated Augmentation
Batch augmentation 이후 제시된 방법으로, \(B\)가 batch size일 때 \(\lceil {B\over m}\rceil\)개의 이미지를 뽑아 하나의 이미지당 \(m\)개의 이미지로 augmentation해 사용한다. sample이 dependent해져 batch size가 작으면 효과가 별로지만 batch size가 크면 i.i.d하게 뽑는 원래의 방법보다 효과가 좋다고 한다.
-
-
Fine-tuning at Different Resolution
224x224로 pre-train 후 384x384로 fine-tune하는, ImageNet에 대해 널리 쓰이는 방식을 썼다고 한다. 다만 fine-tuning 도중 positional embedding을 interpolation하게 되는데, bilinear interpolation을 쓰면 l2-norm of a vector가 감소하여 accuracy에 상당한 감소를 초래한다고 한다. 그래서 DeiT에서는 bicubic interpolation을 썼다고 언급한다.
7. Conclusion
본 논문에서 제시한 DeiT는 transformer에 기반함에도 pre-train에 초대형 데이터셋을 요구하지 않는다. 이는 훈련과 distillation에 있어 향상된 절차 덕분이다. CNN은 장기간에 걸쳐 최적화되었지만, DeiT는 거의 convnet에 대해 이미 존재하는 data augmentation 방법과 regularization 방식만을 사용했지만 좋은 성능을 보였다.
PR-297에서 제시하는 Reference