Patches Are All You Need
쓰고 보니 인칭이 좀 이상한데, '우리'는 내가 아니라 이 논문 저자를 이른다고 보면 된다.
Abstract
ViT는 성공적이었으나, 이것의 성공은 Transformer Architecture 덕분이었을까 patches 덕분이었을까? 본 논문에서는 후자에 무게를 둬 MLP-Mixer과 비슷한 Conv-Mixer을 제시한다. 여기에서 mixing steps에는 standard convolution만을 사용했다. 결과적으로 ViT, MLP-Mixer, ResNet 등을 뛰어넘는 성능을 보였다.
1. Introduction
2020년 Transformer 기반의 ViT가 제시되었고 이는 기존의 convolutional architecture을 뛰어넘는 결과를 보였다. NLP에서처럼 Vision task에서도 이대로 Transformer based architecture가 주류가 되는 것은 시간 문제로 보였으나, NLP와 달리 vision task에서는 이미지를 입력으로 넣을 때 신경을 조금 써줘야 한다. Attention의 naive한 time complexity는 $O(N^2)$, quadratic하므로 이미지를 그대로 넣으면 연산량이 너무 커 patches로 나눈 후, linearly embedding해 입력으로 넣어줘야 한다.
우리는 ViT의 강력한 성능이 patches에서 나오는 것이 아닐까 하는 의문에 더불어, MLP-Mixer와의 유사성에 본떠 ConvMixer라고 이름 지은 간단한 convolutional architecture을 제시한다. 이것은 직접적으로 patch에 작용해 모든 레이어에 걸쳐 equal-resolution-and-size representation를 유지한다. 그리고 channel-wise mixing과 spatial mixing을 구분한다. 그러나 우리 architecture은 standard convolution으로만 작동한다.
우리가 낸 주된 결과는, 6줄에 달하는 간단한 pytorch implementation만으로 ResNet과 같은 standard model과 ViT, MLP-Mixer을 뛰어넘는 것이다 (비슷한 parameter 수에서). 앞으로 “convolutional-but-patch-based”가 주류가 되리라 생각한다.
2. A Simple Model: ConvMixer
구조는 매우 간단하다.
-
Patches로 나눈다.
이 때도 3 channel→h channel, stride & kernel size
patch_size인 convolution 연산을 사용한다 -
depth번만큼,
Depthwise Convolution+Pointwise Convolution을 반복한다. Depthwise Convolution은 spatial location의 mix, Pointwise Convolution은 channel location의 mix를 하기 위해 시행한다. 중간중간 Activation+Batch Norm 넣어준다.
-
Global Average Pooling후, (1, 1, h) 벡터를 linear transform해 classification 값을 얻는다.
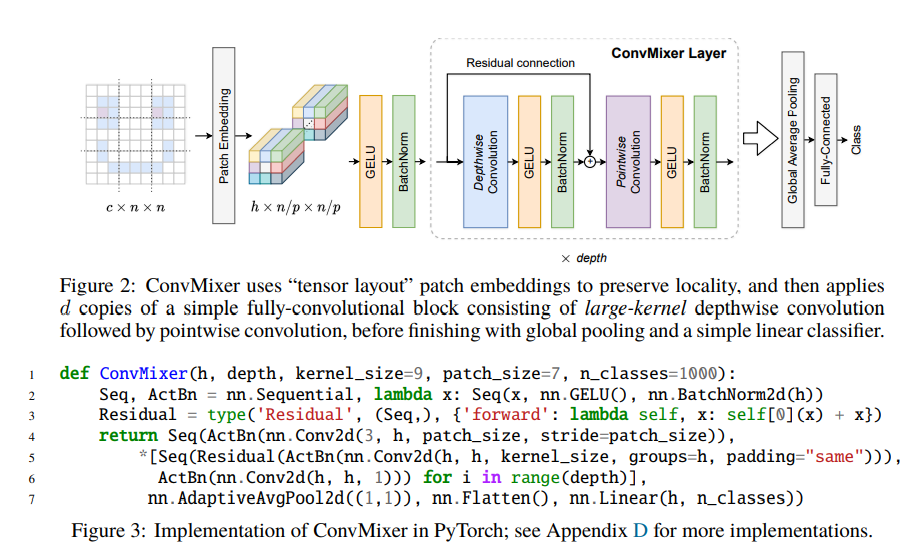


여러 실험에서 주요한 하이퍼파라미터는 hidden dimension h, depth d, kernel size(of depthwise convolution) k, patch size p가 있다. global한 특성을 가지는 self-attention에서 따와, kernel size of depthwise convolution은 기존의 그것보다 굉장히 넓게 설정했다. (Table 1을 보면, kernel size를 거의 $n/p=32$의 1/4정도로 설정했다.)
본 논문에서 ConvMixer-$h/d$를 표기하는데, 여기의 $h,d$는 위에 말한 hidden dimension과 depth이다.
3. Experiments
-
Training Setup:
timm framework를 이용해 RandAugment, mixup, CutMix, random erasing, gradient norm clipping을 default timm augmentation에 더해 사용했다.
그런데 hyperparameter tuning을 안 했다고 한다. ㄷㄷ..
-
Results
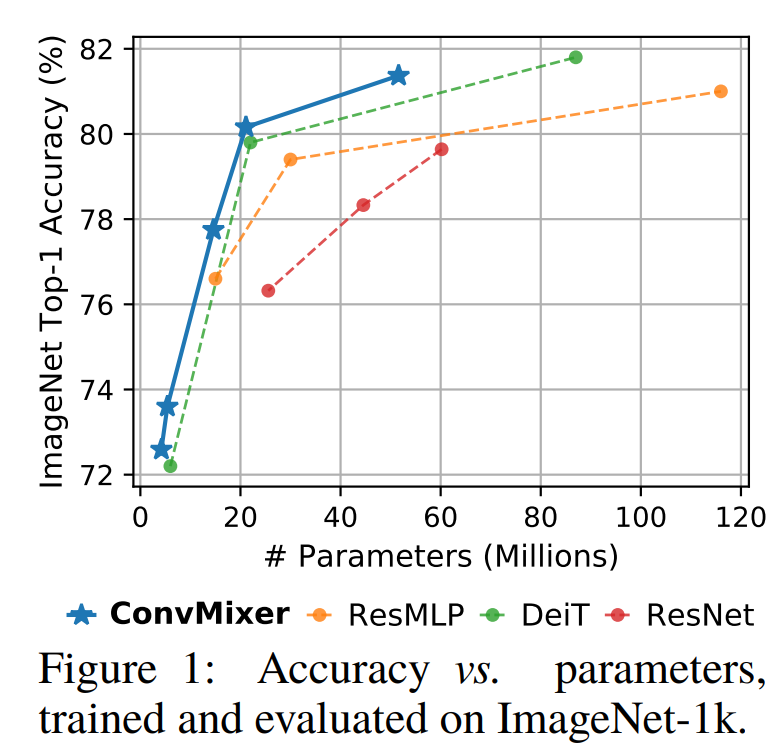
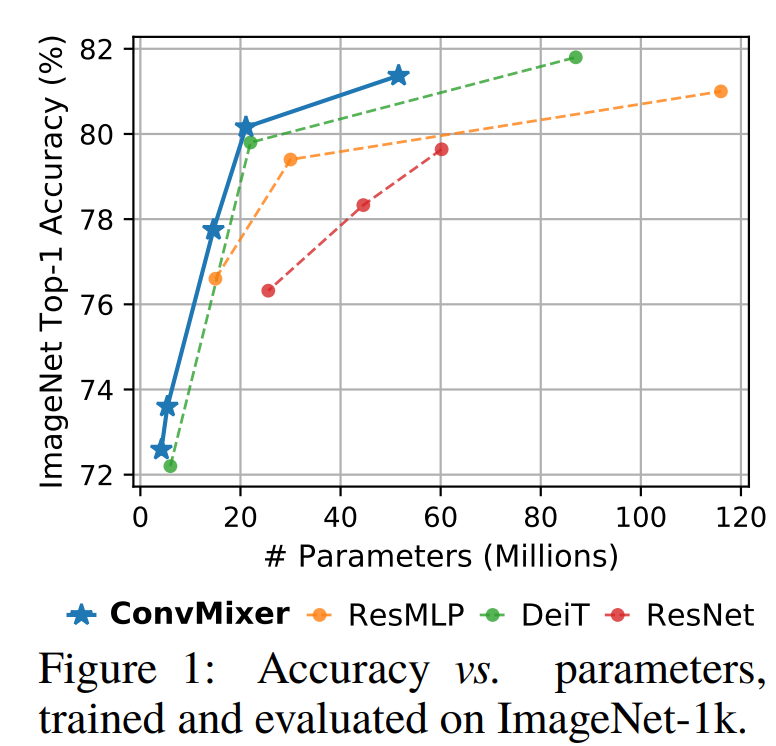
ConvMixer-1536/20은 52M parameter로 ImageNet top-1 accuracy 81.4%를 달성한다. ConvMixer-768/32는 21M parameter로 80.2%를 달성한다.
kernel size가 클 때 잘 되었고, smaller patches일 때(patch로 나누지 않고 넣을 때와 비슷해질 때) 더 결과가 잘 나온다고 한다. larger patches에서 결과가 잘 나오려면 deeper해야 한다고 생각한다고 한다.
patch-size를 7에서 14로 키우면 ConvMixer-1536/20은 top-1 accuracy 78.9%지만 4배나 빨라졌다고 한다. Mobile에도 사용 가능할까?
-
Comparisons
parameter 수를 비슷하게 해서 훈련시켰을 때, DeiT와 ResMLP는 ConvMixer와 다르게 hyperparameter tuning이 되어 있음에도(특히 ResNet은 tuning하는데 지금까지 엄청난 자원이 소모되었음에도), epoch도 2배임에도 ConvMixer을 0.2%밖에 outperform하지 못했다고 한다.
-
CIFAR-10 Experiments
0.7M의 적은 parameter로 CIFAR-10에서 96% 넘는 정확도를 얻었다. 이는 Convolutional inductive bias의 data efficiency를 증명한다.
4. Related Work
Related Work가 2번이 아니라 4번에 나오는 조금 보기 힘든 구조를 가지고 있다.
-
Isotropic architecture
ViT는 네트워크에 걸쳐 equal size와 shape를 사용하는, isotropic architecture의 paradigm을 열었다. 이후 MLP-Mixer, ResMLP등이 나왔다. 다만, ConvMixer에의 조사가 제시했듯 이러한 작업들이 self-attention, MLP와 같은 새로운 operation의 효과와 patch embedding의 사용과 그로 인한 isotropic architecture의 효과를 융합해서 생각해버렸을 수 있다.
의역하자면, self-attention, MLP등이 중요하다기보다 patch embedding과 isotropic architecture이 중요한데 그 점을 무시하지 않았나 지적하는 듯하다.
-
Patches aren't all you need.
여러 paper에서 ViT의 performance를 standard patch embedding을 다른 것으로 바꾸면서 향상시켰다. 예를 들어 인접한 patch embedding을 combine하는 연구가 있었으나, 다만 이러한 연구는 locality inductive bias의 효과와 patch embedding의 효과를 함부로 합쳐 버렸을 가능성이 있다. 그래서 우리는 patches의 쓰임새에 집중했다.
-
CNNs meet ViTs
지금까지 CNN을 ViT에 합치려는 노력은 계속되어 왔다.
self-attention이 convolution을 emulate할 수 있다는 연구도 있었고, attention이 convolution 비슷하게 작동하도록 initialized되거나 regularized 될 수 있다는 연구도 있었고(
이거 내가 생각하던 건데 역시 이미 있네..), 단순히 convolution operation을 transformer에 더하려는 연구도 있었다(이것도 생각하던 건데). 그리고 pyramid-shaped convolutional network를 본떠 transformer에 downsampling을 포함한 것까지 있었다.다들 나름의 성과가 있었으나 본 연구와는 방향이 다르다.
5. Conclusion
본 논문에서는 독립적으로 spatial and channel location of patch embedding을 standard convolution만을 이용해 mix하는, 극도로 간단한 모델인 ConvMixer을 제시했다.
특히 ViT와 MLP-Mixer의 large receptive field에 착안하여 large kernel size를 사용했으며 이는 상당한 성능 향상에 기여하였다.
우리는 hyperparameter tuning을 하지 않았음에도 ViT와 MLP-Mixer을 추월해 ResNet, DeiT, ResMLP와 경쟁력이 있었다.
논문의 길이가 짧지만 Patches를 이용한 접근을 제안했다는 점에서 충분하다고 한다.
A. Comparison to Other Models
-
ResNets
ConvMixer가 accuracy가 상당히 높았다.
ReLU의 영향인가 했지만 GELU에서 ReLU로 바꿔도 차이가 컸다.
하지만 throughput이 ConvMixer가 훨씬 적다.
-
DeiT ↔ ViT으로 보고 ConvMixer와 비교,
-
ResMLP ↔ MLP-Mixer으로 보고 ConvMixer과 비교하므로 관심 있는 사람은 읽어보자.
나는 DeiT, ResMLP 논문을 향후 읽어볼 예정.
B. Experiments on CIFAR-10
모든 결과는 ImageNet과 같은 큰 크기의 이미지의 데이터셋이 아닌 CIFAR-10 기준임에 유의.
-
Residual Connections
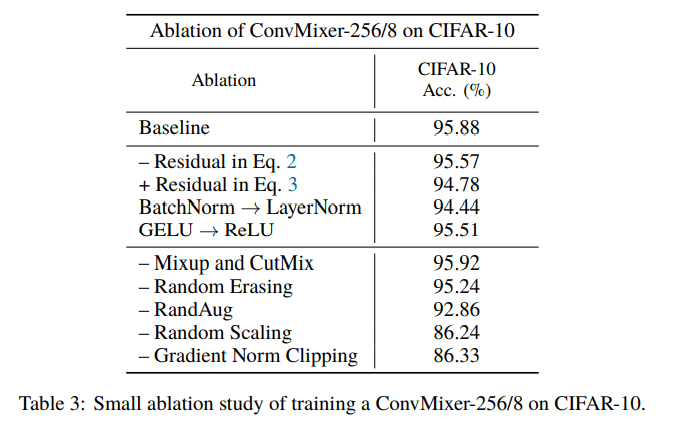
놀라운 점은 Residual Connection을 아예 제거하였을 때 0.31% decrease밖에 없었다는 점이다.
기타 결과는 Table 3 참고.
특이한 점이자 기억할 만한 점은, Augmentation Methods중 RandAug, Random Scaling이 굉장히 큰 영향을 준다는 것이다. 95%에서 86%까지 떨어진다.
-
Normalization
MLP-Mixer와 ViT에서는 LayerNorm을 쓰지만, ConvMixer에서는 LayerNorm을 썼을 때 1%의 성능 하락과 느린 수렴을 관찰하였다. 다만 이는 상대적으로 얕은 모델에게 그랬고, LayerNorm이 ImageNet-scale model을 비교할 지는 보증할 수 없다고 논문에서는 서술한다.
B.1 Results
-
Scaling ConvMixer
-
Kernel size
MLP나 self-attention을 본떠 larger-than usual kernels을 사용했을 때 결과가 좋을 것으로 예상했고, 그렇게 결과가 나왔다. (kernel size 3→5 $
+1.5\%$, 5→7+0.61%, 7→15+0.28%)내가 궁금했던 점에 대해서도 서술한다. large-kernel convolution이 stacked small-kernel convolution으로 decomposed 될 수 있다는 것이다. 특히 기존의 연구에서는 nonlinearity를 더욱 잘 만들어 주기 위해 그렇게 해왔었다.
This raises a question: is the benefit of larger kernels in ConvMixer actually better than simply increasing the depth with small kernels?
deeper network는 generally harder to train하고, 따라서 kernel size를 증가시킴으로써 신호가 역전파되기 힘든 상황을 조성(deeper network)하지 않고도 deeper network의 이점을 챙길 수 있다.
이 가설을 테스트하기위해 (1) parameter 수가 비슷하고 kernel size 1/3 (2) 깊이가 3배고 kernel size가 1/3 두 경우를 모두 원래 모델과 비교했지만, 원래 모델에 비해 정확도가 낮았다.
-
Patch size
CIFAR-10에서 patch size는 1을 사용했으며, patch size를 늘릴수록 accuracy가 감소했다.
larger patch에서 larger kernel은 덜 중요할 것이라 생각했고 그렇게 결과가 나왔다고 한다.
D. Implementation

참고 자료
 labmlai
labmlai