Perceiver: General Perception with Iterative Attention
Abstract
생물학적 시스템에서는 시각, 청각, 촉각, 자기수용감각 등 다양한 양상의 고차원 입력을 받아 동시에 처리해 세계를 인지한다. 그러나 딥러닝의 인지 모델은 각각의 양상을 위해 디자인되었으며 vision model의 local grid structure과 같은 domain-specific assumptions에 자주 의존한다.
이러한 전제는 유용한 inductive bias를 만들어 내지만 각각의 모델들을 각각의 양상에 한정시킨다. 본 논문에서는 Transformer 기반으로 architectural assumption 없이 작동하는 Perceiver을 소개한다.
이 모델은 asymmetric attention mechanism을 이용해 지속적으로 입력을 tight한 잠재벡터에 distill하고, 이는 매우 큰 입력도 모델이 처리할 수 있도록 만들어준다.
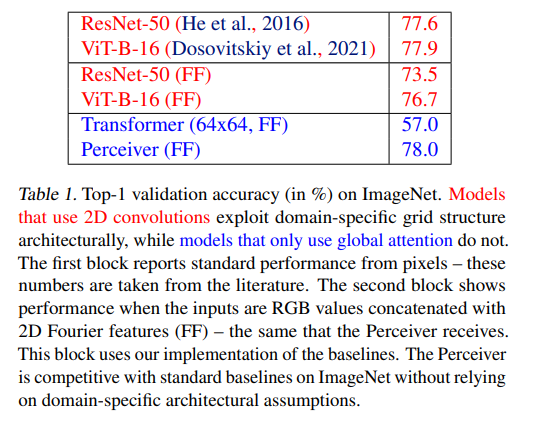
이 논문에서는 Perceiver가 image, point clouds, audio ,video, video+audio에 걸쳐 다른 모델과 경쟁력 있음을 보였으며, 특히 50000 pixels를 직접적으로 사용함으로써 ResNet-50과 ViT에 비교할 만한 성능을 얻어냈다. 또한 AudioSet의 모든 양상에 대해 경쟁력이 있었다.
1. Introduction
그간 여러 모델에 설정된 architectural assumption과 그에 의해 발생하는 inductive bias는 모델의 성능을 극적으로 높여 주었다. 그러나 이렇게 모델을 설계하면 input이 변할 때마다 architecture을 다시 디자인해야만 하는 단점이 있다. 예를 들어 2D convolution을 사용한 모델은 3D Point Cloud에 적용하기에는 적합하지 않다.
이 논문에서는 하나의 Transformer-based architecture로 다양한 종류의 입력을 처리할 수 있는 Perceiver을 제시한다. 이전에도 Transformer을 사용한 연구는 있었지만 $O(N^2)$의 attention의 시간복잡도에 걸려 데이터를 직접적으로 처리하지 못하고 다른 해결책을 모색한 경우가 많았다. 이 논문에서는 이러한 한계점을 해결했다.
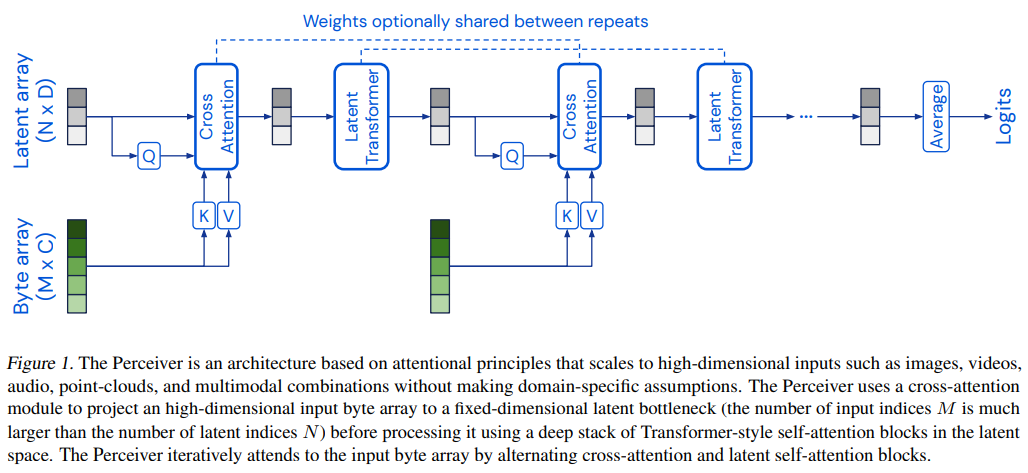
핵심 아이디어는 attention bottleneck을 형성하는 small set of latent unit를 형성한 후, 여기에 cross-attention을 통해 입력의 정보를 전달하는 것이다. 이것은 all-to-all attention의 quadratic scaling problem도 해결하고, 입력 사이즈와 모델 깊이를 분리시켜 매우 깊은 모델도 만들 수 있도록 한다.
position과 modality-specific feature은 learned되거나 Fourier features를 통해 만들어질 수 있다. (Transformer등 여러 논문을 근거로 제시한다)
3. Methods
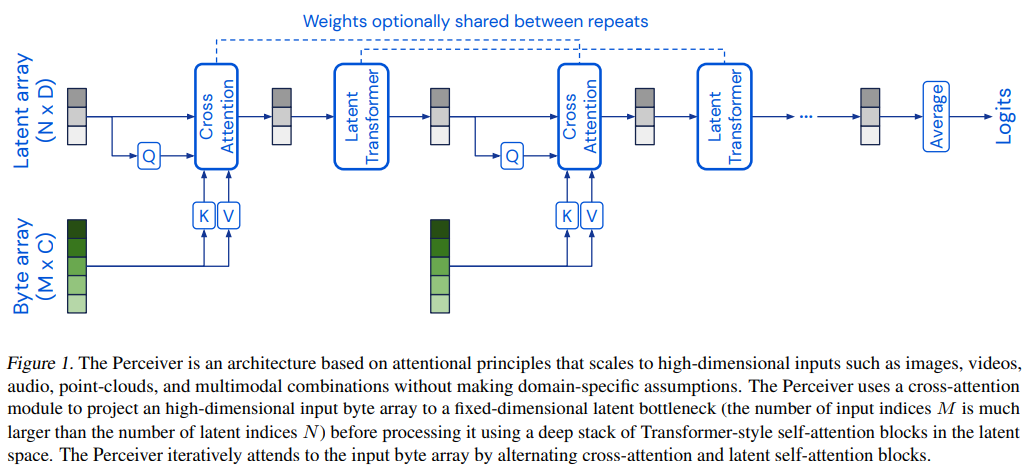
3.1 The Perceiver architecture
-
Overview
ImageNet등은 50176 pixel로 꽤 큰 편이지만, 본 모델의 latent vector은 512 정도로 작은 사이즈를 사용한다. 본 모델은 cross attention과 transformer을 번갈아 사용하며, 이것은 deep Transformer에 데이터를 처리하기 전 고차원 byte array(입력)를 lower-dimension attention bottleneck을 통해 projecting해주는 것이라 할 수 있다. 특히 Transformer간의 가중치를 공유할 경우(이것은 선택사항임) RNN과 같이도 해석이 된다. 다만 시간에 따른 입력을 넣기보다 같은 입력을 넣어 depth에 대해 unroll한다고 언급한다. 또 transformer에서 mask를 쓰지 않아 non-causal하다고 언급한다.
-
Taming quadratic complexity with cross-attention
ImageNet은 $M=50176$이고 표준 sampling rate의 1초 오디오 데이터는 50000개의 오디오 샘플에 해당한다. QKV attention은 기본적으로 입력에 quadratic complexity로 작동하며 이러한 데이터를 처리하기에는 무리가 있다.
그래서 이 논문에서는 입력을 attention에 KV로만 넣고 Q는 소형의 latent vector을 사용함으로써, $O(NM)(N <<M)$의 time complexity를 따르게 했다.
-
Uncoupling depth with a latent Transformer
Transformer은 $O(N^2)$를 처리하는데 이때 $N=512$정도로 작기에 Transformer의 처리 비용은 적다.
입력 크기와 depth를 decoupling함으로써 large-scale data에 대한 very large network를 만들 수 있다고 언급한다.
latent array는learned position encoding을 통해 initialized된다고 언급한다. (Gehring et al., 2017)
-
Iterative cross-attention & weight sharing
cross-attention을 통해 입력에 대한 정보를 지속적으로 공급해야 하지만, 동시에 이게 잦아지면 입력 사이즈에 선형인 처리량이 많아지므로 적절히 조절해야 한다고 언급한다. (Appendix Tab.6 참고)
또 cross-attend module 사이의 latent Transformer의 weight를 공유함으로써 parameter efficiency를 올릴 수 있다고 언급한다.
3.2 Position encodings
attention은 permutation-invariant한 연산자이고, 따라서 순서와 관련된 공간적/시간적 정보를 넣어주기 위해서는 positional encoding을 해야만 한다. 이는 인접한 픽셀에 대한 inductive bias를 포함한 ConvNet과는 반대된다.
그래서 이전 연구에서도 그래왔듯 이 연구에서도 Fourier feature position encodings을 넣어준다.
4. Experiments
DeppMind의 JAX ecosystem을 이용해 실험을 진행했다고 서술한다.
4.1 Images - ImageNet
ImageNet은 224*224 pixel crop을 포함하는 Inception-style preprocessing으로 샘플링하고, 여기에 RandAugment를 더했다고 한다.
-
Position encoding
흥미로운 내용을 제시하는데, crop을 했을 때 원래 이미지의 position을 crop 후의 position 대신 사용하면 (RGB, position) feature을 기억해버려서 overfitting을 한다는 것이다.
어떤 정해진 position에 어떤 정해진 RGB값이 존재하는 입력과 레이블 쌍이 많지는 않을테니 그럴 수 있다는 생각이 들었다.
그래서 crop 이후의 위치를 기반으로 [-1, 1]의 position 값을 사용해줬다고 한다.

-
Optimization and hyperparameters
첫번째 cross-attention의 weight를 뒤따르는 cross attention과 공유하면 안정성 문제가 있어 첫째 cross-attention만 weight sharing을 하지 않았다고 언급한다.
-
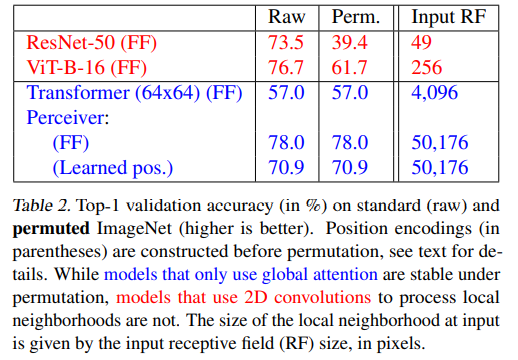
Permuted ImageNet
positional encoding후 permutation을 가해줬더니 transformer 기반의 네트워크는 역시나 정확도가 안 변했다는 이야기를 한다. 당연히 ConvNet은 변했고 정확도가 확 떨어졌다.
그리고 묘한 이야기를 하는데, positional encoding을 learned parameter로 바꿨더니
we can evaluate the performance of a Perceiver**with no knowledge of the spatial structure of the**라고 굉장히 이상한 이야기를 한다. 내가 잘못 이해한 게 아니라면 positional encoding을 학습 대상으로 바꿨더니 positional encoding이 없는 것과 같은 효과를 냈다는건가? 이러한 learned positional encoding은 위치에 대한 정보가 없어 그냥 positional encoding 없이 훈련한 것과 같은 효과를 낸다고 7p에서 언급하는데, 내가 알기로 transformer에서 learned encoding을 써도 학습이 잘 되었던 걸로 기억해 혼란이 온다. 그냥 단순히 학습이 되긴 되는데 Fourier Feature처럼 완전히 학습이 되지 못한 게 아닐까 싶다. 내 뇌피셜이니 이건 다른 사람 확인이 필요할 듯.
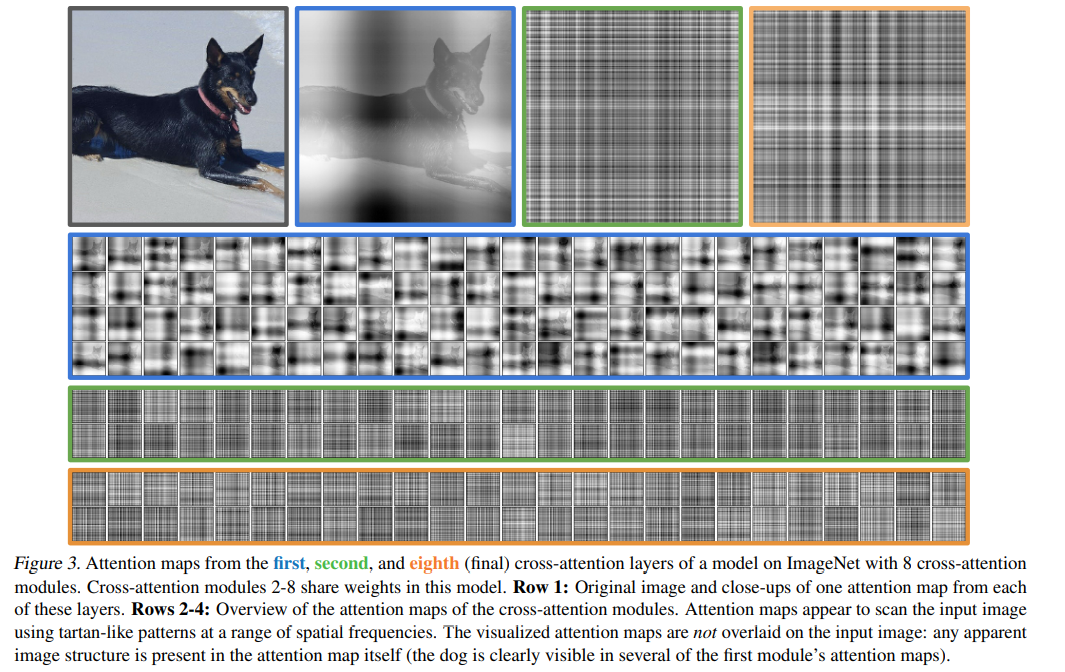
-
Attention maps
1번째 cross-attention에서의 attention map에서는 개의 형상과 어디에 attend하고 있는지가 인간이 인지할 수 있을 정도로 표시가 된다. 이후 2~8까지 cross-attention의 attention map은 high-frequency로 나타나 인간이 해석하긴 힘들어 보인다.
4.2 Audio and video - AudioSet
AudioSet은 1.7M의 10초의 긴 training video와 527 classes로 이루어져 있다.
이 모델에서는 1.28s at 25fps에 해당하는 32-frame clip을 16개(overlapping하도록) 따 입력으로 넣어 전체 10초를 커버한다고 한다. 각각의 clip에 대해 averaging the scores를 했고, 100 epochs 동안 학습했다고 언급한다.
cross-attend마다 one frame을 넣는, 'temporal unrolling' 방식으로도 간단하게 실험을 해봤다고 언급하는데, video에는 잘, 그리고 효율적으로 작동하나 audio에 대해서는 성능이 저하되었다고 언급한다. 이후 Audio may require longer attention context라고 언급한다. 아마 audio의 길이를 늘려야 한다고 말하는 것인듯하나 확실하진 않다.
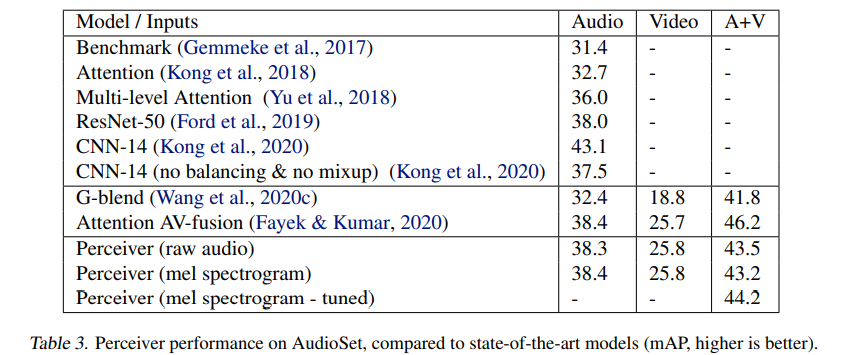
Table 3에서 성능지표를 제시하나, 이쪽 지표는 내가 잘 몰라서 잘 나온건지 모르겠다.
4.3 Point clouds - ModelNet40
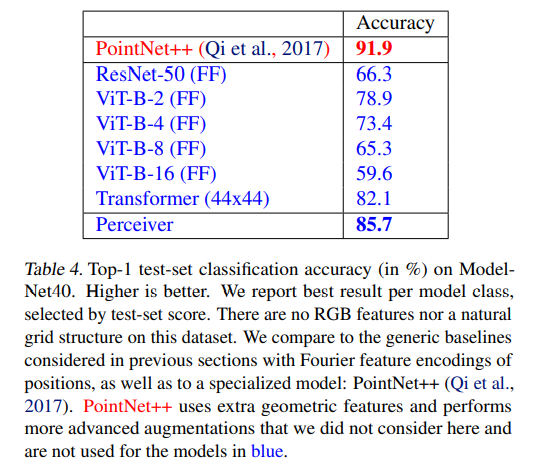
개선방안을 더 적용하면 성능이 올라갈지도 모르겠지만.. 일단 최근 SOTA와 비교하면 그렇게 엄청난 accuracy를 보여주진 못한다.
5. Discussion
Future work에서, 대용량 데이터에 대해 pre-train도 해보고 싶다고 언급한다.
또 modality-specific prior knowledge in the model을 줄이긴 했으나 아직도 modality-specific augmentation과 position encoding을 사용해야 한다고 언급한다. End-to-end modality agnostic learning은 아직 흥미로운 연구 방향으로 남아 있다고 언급한다.
C. Architectural details
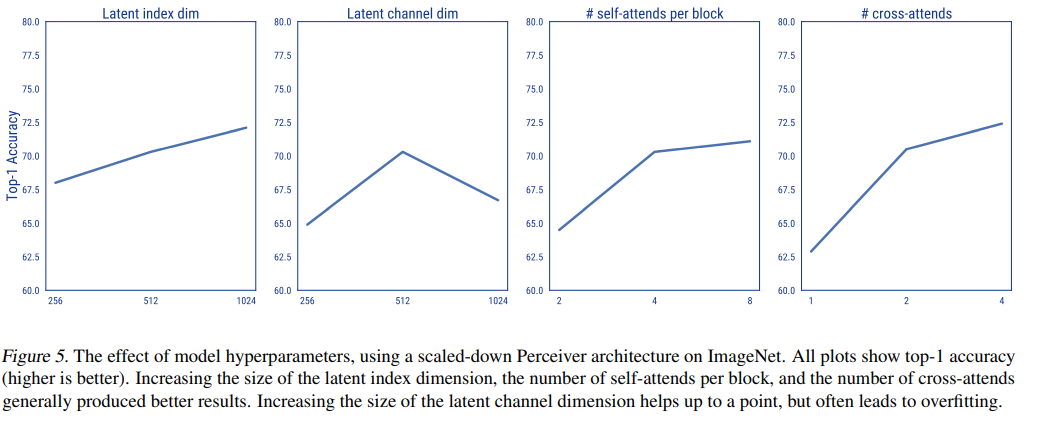
Weight sharing 없이 구성했을 때 간혹 overfitting이 일어나는 경우도 있었고, latent channel dim을 늘릴 때도 overfitting이 일어났다고 한다.
그 외에 latent index dim, # self-attends per block, # cross-attends를 늘리면 정확도가 상승했다.
특히, cross attention을 1번에서 2번으로 늘릴 때 정확도가 확 상승했다.