The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning
https://blog.otoro.net/2022/10/01/collectiveintelligence/ 에서 처음 읽어서
https://attentionneuron.github.io/ 로 흘러오고
https://www.youtube.com/watch?v=7nTlXhx0CZI 을 보며 정리한 글이다.
발상
인간은 핸들을 꺾는 방향과 앞바퀴의 움직임이 반대인 'reverse bicycle'이나 upside-down 반전된 환경에서도 적응 시간이 있으면 적응 할 수 있다고 한다. 또한 시각장애인이 전동을 앞뒤로 전달하는 장치를 통해 '볼' 수 있다고 한다.
이러한 인간의 특성에서 착안해 sensory substitution, 입력 신호의 치환이 가능한, input permutation invariant한 RL structure을 제 시한다.
Background
-
Permuation invariance
임의의 permutation $s$에 대해, 아래 특성을 만족하는 함수들을 permuation invariance하다고 한다.
$$\{f: \mathbb{R}^n \rightarrow \mathbb{R}^m | f(x[s]) = f(x)\}$$ -
Set Transformer
기존의 transformer 연산은 permutation invariant하지는 않다. 기존의 transformer을 알고 있는 사람 중 "transformer은 input 순서를 모르는 게 아닌가?" 싶어서 이게 뭔 소리인가 싶은 사람이 있을 텐데, 지금 말하는 permutation invariance는 언제든 입력의 순서를 바 꿨을 때 똑같은 출력이 나오는 것을 말한다. 기존의 transformer은 분명히 1번째 입력이 2번째 입력보다 '앞에' 있음은 모르지만 1번 째 입력과 2번째 입력의 순서를 바꾸면 출력도 1번째 출력과 2번째 출력이 바뀌어 나온다.
이를 해결하는 방법은 간단한데 그냥 $Q$만 input에 independent하게 만들어주면 된다.

AttentionNeuron Layer
기존 RL에서는 이전의 action $a_{t-1}$와 현재의 observation $o_t$를 policy $\pi$에 입력으로 넣어 다음 action $a_t$를 구하는데, 이 논문에서는 policy $\pi$ 직전에 permutation-invariant한 'AttentionNeuron' 모듈을 끼워넣어 문제(?)를 해결한다.
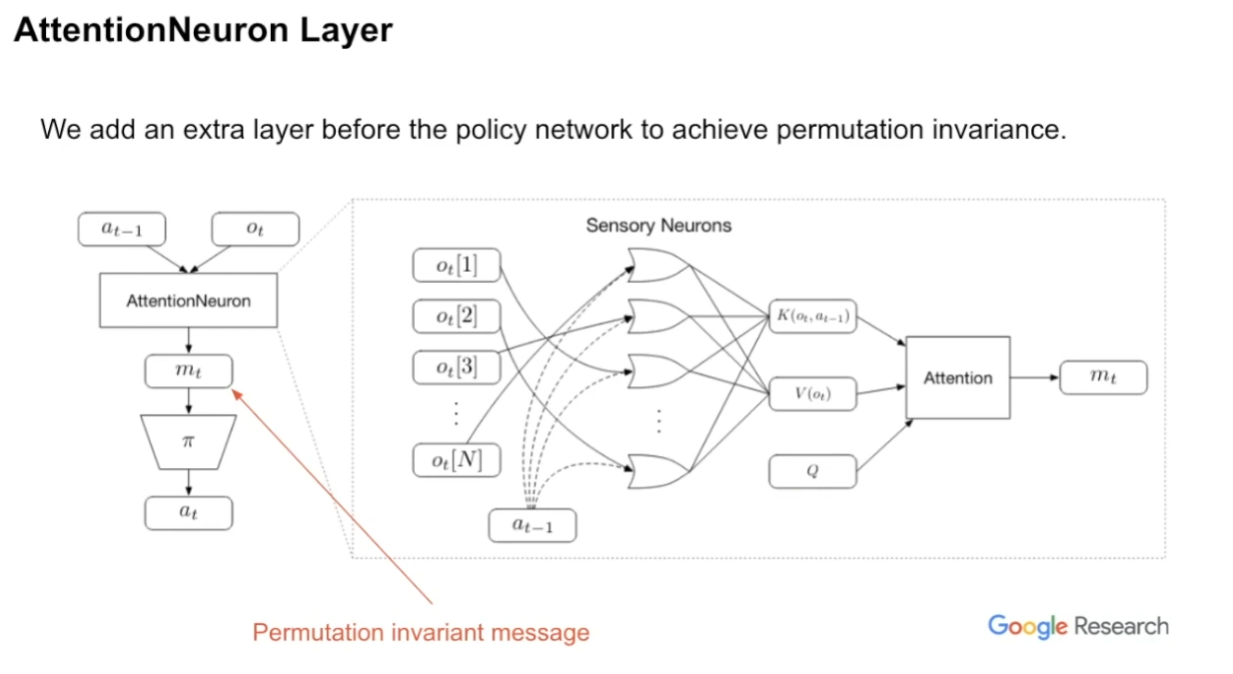
보면 알겠지만 $m_t$는 'permutation invariant message'이다.
AttentionNeuron은 그림의 오른쪽처럼 생겼는데, input independent한 Q와 $(o_t, a_{t-1})$에 의존하는 $K$, $(o_t, )$에 의존하는 $V$를 이용해 QKV attention하여 출력 $m_t$를 출력하는 구조이다.
why $a_{t-1}$ on $K$?
"각 $o_t[i]$에 대한 정보를 더 상세하게 넣어주기 위함"으로 보인다. 더 자세히 설명하자면, AttentionNeuron 모듈은 permutation-invariant하기에 입력된 signal이 어떤 signal인지 interpret하고 identify하기 힘들다고 한다. 예를 들어 로봇 조종하는 예시에서, 각 관절의 velocity를 입력으로 넣고는 하는데, 그러한 입력은 서로 크게 다르지 않아 구분하기 힘든 경우가 있다고 한다.
그래서, 각 signal을 identify & interpret하기 위해 $K, V$에 temporal memory를 넣어줘야 하는데, 이를 Key creation 과정에 previous action을 끼워넣어 해결했다고 한다.
나는 처음 이 부분을 보고 이해가 가지 않았는데, 왜냐면 이렇게 하면 'permutation-invariant하게 만들자!'는 처음의 동기가 훼손되기 때문이다. 애당초 영상에서 네다리 로봇이나 cartpole이 input을 permutation시키면 잠깐동안 이상해지는데, 이 논문에서 다루는 것이 "완벽하게 permutation-invariant한 모듈"이라 이해해서 그것 자체가 이해가 가지 않았었다. 아무튼 이러한 design choise를 따랐기 때문에 사실 이론상 완벽히 permutation-invariant하지는 않고, temporal memory를 가진다. "Temporal" memory기에 괜찮다고 하면 또 뭐 할 말은 없지만. 뭐 저자가 이렇게 했다는데 내가 할말은 없긴 하지..
사실 저자 입장에서도 아마 '$a_{t-1}$를 넣지 않고 해보니까 잘 안되서'가 가장 처음의 동기가 아니었을까? 아님 말고..
AttentionNeural의 특징
각 observation의 feature을 늘려도 output의 모양에는 전혀 영향을 주지 않는다. observation shuffling은 K와 V의 순서에만 영향을 줄 뿐이다. (Attention 과정에서 정보가 병합되므로 $m_t$에는 영향이 없다.)
Results
interactive demo를 https://attentionneuron.github.io/ 에서 확인할 수 있다.
cart-pole swing up

뭐 크게 놀라운 점은 없다. 입력이 shuffle되는 상황 없이는 baseline보다 좀 못하고, shuffle되면 당연히 baseline보다 훨씬 잘하고, 일부 noise input이 observation 중에 들어오면 baseline보다 훨씬 잘한다.
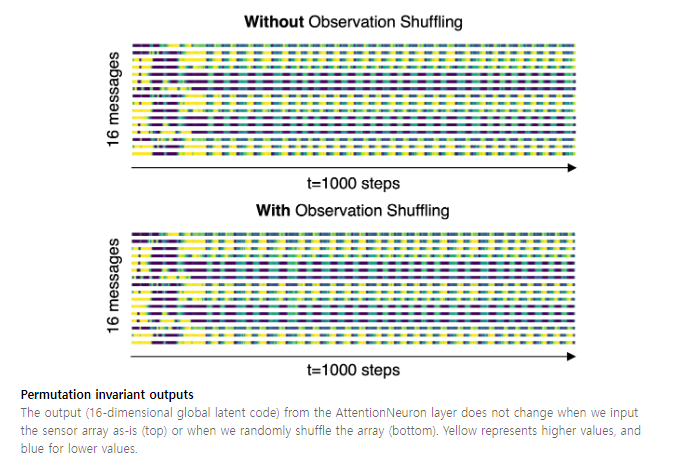
그리고 permuation invariant하다는 점을 보여주기 위해 위 plot을 보여주는데...
좀 이상하다. Using the same environment seed, we keep the observation as-is in the first test but we shuffle the order in the second. 라고 하니 두번째 그림은 시작 전에 observation permutation을 하고 진행했다는 뜻으로 보이는데, 이건 set transformer가 아니라 transformer 구조를 차용했어도 똑같았을 텐데? 시뮬레이션을 시작한 후에 permutation을 했으면 message에 요동이 있었을테니 아 마 시작하기 전 permutation을 한 게 맞을거다.
음...?? 아무튼 그렇다고 한다.. 내 생각이 틀린 거라면 누군가 알려줬으면 좋겠다.
아래 표는 정확히 어떤 식으로 그렸다는 건지 이해하지 못했다.

PyBullet Ant
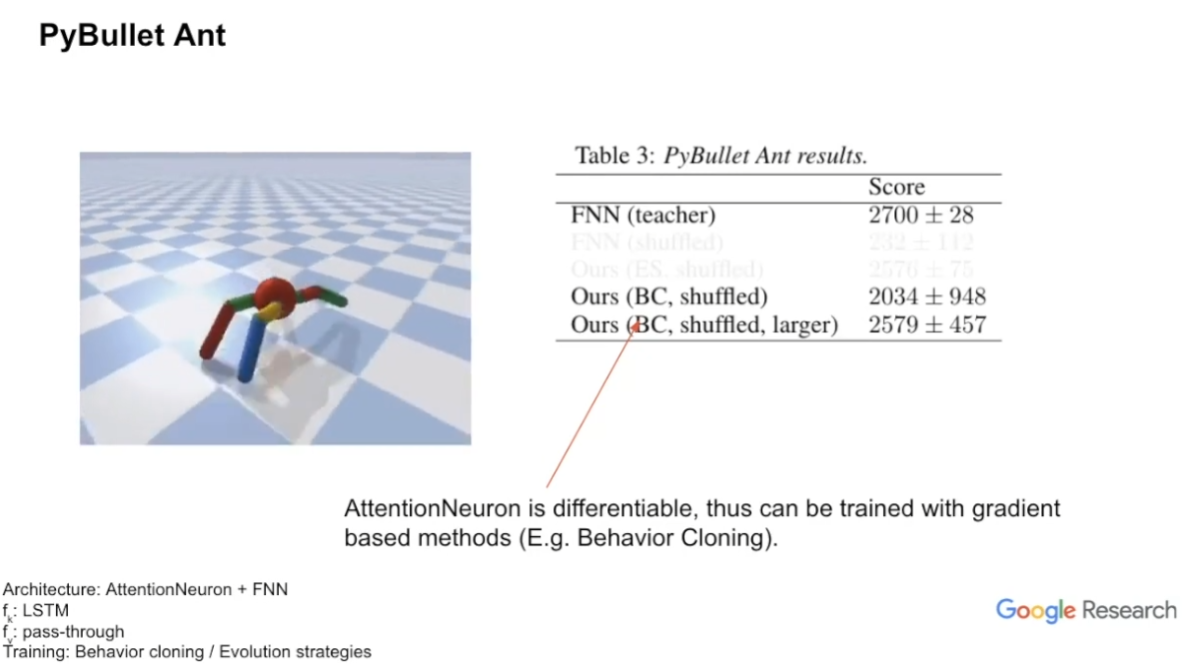
크게 신기한 결과는 없다. 그냥 AttentionNeuron이 differentiable하다 정도가 좀 중요할까..
Atari Pong
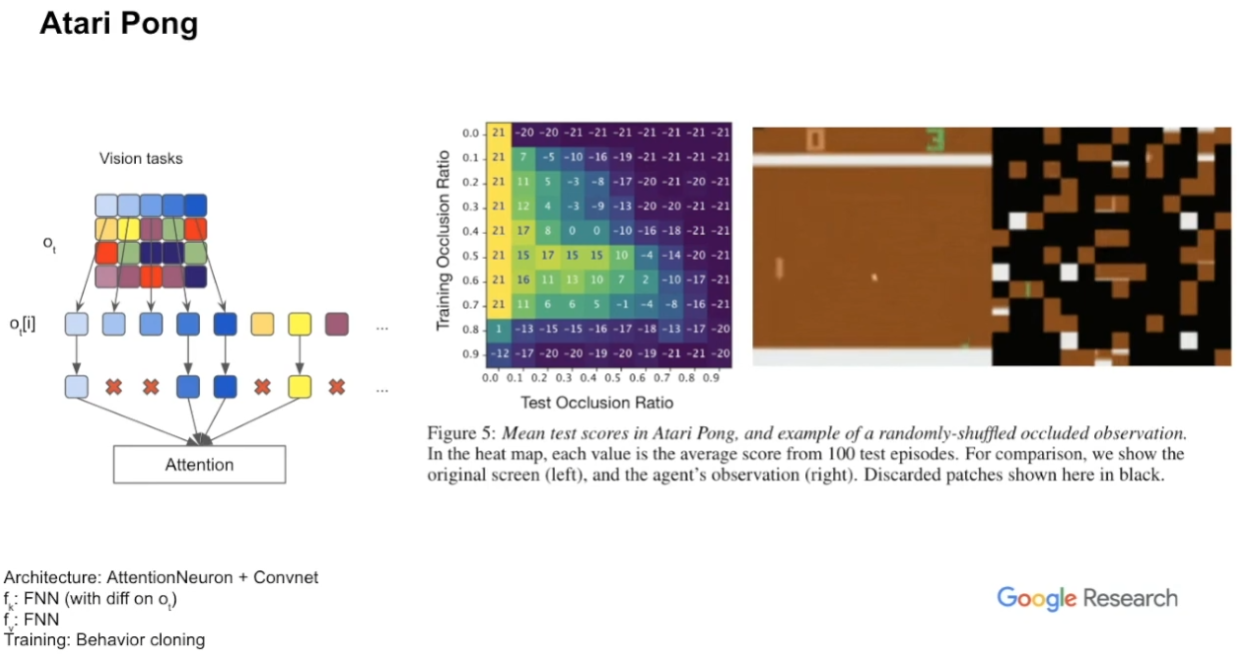
occlusion ratio를 학습 시에는 좀 크게, test 시에는 좀 낮게 설정하면 좋은 성능을 얻을 수 있었다고 한다.
CarRacing

unseen scenarios에 대해 zero-shot generalization이 잘 됨을 보여준다.
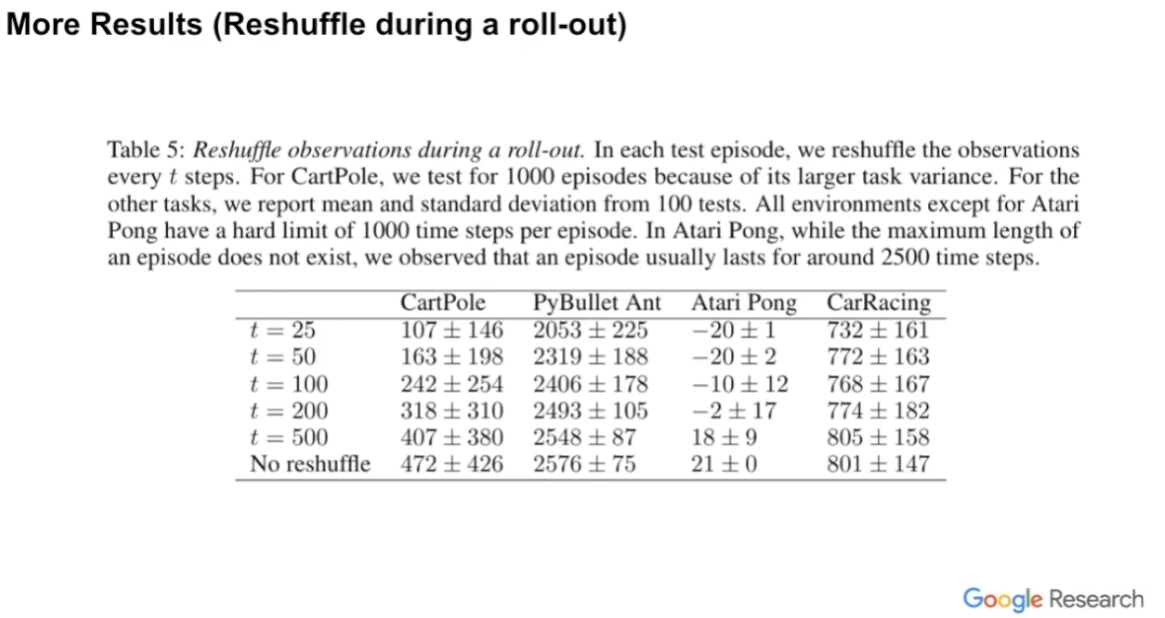
Reshuffle during a roll-out
초기 입력 identification을 학습할 때 shuffle을 반복하면 좋지 않은 성능이 나옴을 보여준다.
Conclusion


후기
뭐랄까, "이미지 패치를 전부 셔플해도 원래와 똑같이 작동할 수 있다"는 문구에 어그로가 끌려 잔뜩 기대하고 봤지만 생각보다는 신기 하지 않았으며 뭐 그래도 흥미롭기는 했던 그런 연구 같다.
https://blog.otoro.net/2022/10/01/collectiveintelligence/ 에서는 "identital sensory neuron unit"에 입력을 넣어 attention으로 처리하는 논문이라면서 collective intelligence 연구로 소개한다. 하지만 개인적으로 이 논문을 읽으며 딱히 그런 느낌이 강하게 들지는 않았던 것 같다. 뭐 그래도 최소한 인간에게 일어나는 sensory substitution 현상 자체는 신기한 듯하다.
그리고 이 연구랑 크게 명시적인 연관이 있진 않은데 왜인지 이걸 읽고 연상되는 논문으로 Vector Neurons: A General Framework for SO(3)가 있다. 뭐 permutation invariant가 키워드인 이 논문과 SO(3) invariant가 키워드인 저 논문이 비슷해서 연상이 된듯. 3D Vision 분야 연구니 궁금한 사람은 읽어보자.