AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
요약
하나의 단어를 $W$개의 스칼라를 가진 벡터로 나타낼 때, 하나의 문장은 이 벡터를 $N$ 개 가진 행렬로 나타낼 수 있다. 이미지는 patch로 나눈 후 $N*N$개의 특징벡터를 가진 "문장"으로 취급할 수 있다. 즉, NLP에서 Transformer의 analogy를 그대로 Image Processing에 적용할 수 있다. 이 아이디어를 이용해 Transformer의 구조를 image recognition에 적용한 모델, ViT를 제안한다.
다만 ViT는 JFT와 같은 대규모 데이터셋을 이용한 pre-training이 필요하다는 한계가 있으며, 향후 이를 해결하기 위해 DeiT와 같은 논문이 제시된다.
들어가기 전에 앞서: Convolution의 한계
Convolution 연산에는 Receptive Field가 존재한다.
즉, 3x3 Convolution 1회 후에는 하나의 스칼라가 3x3영역의 정보밖에 담지 못하며, 이것을 n회 수행하면 보통은 (stride에 따라 달라지지만) receptive field가 넓어지지만 해당 receptive field를 벗어나는 곳에 있는 정보를 반영할 수가 없다.
Attention은 그러한 한계를 극복하면서도 필요하면 멀리, 필요하면 가까이 있는 정보를 적절히 섞어 특징 벡터를 뽑아낼 수 있는 연산이다. (global하다고 표현) 물론 Attention에도 positional encoding이 필요하다는 단점이 있으며 이는 후술한다.
1. Introduction
2017년 Transformer가 제시된 이후로, self-attention을 computer vision에 활용하려는 시도는 여럿 있어왔다. 그러나 ResNet을 뛰어넘진 못해왔다.
본 논문에서는 대용량 데이터셋을 이용한 pre-train후 transfer learning을 통해 convolution 없이 attention만을 이용한 설계로 SOTA를 달성했다.
3.1 Vision Transformer
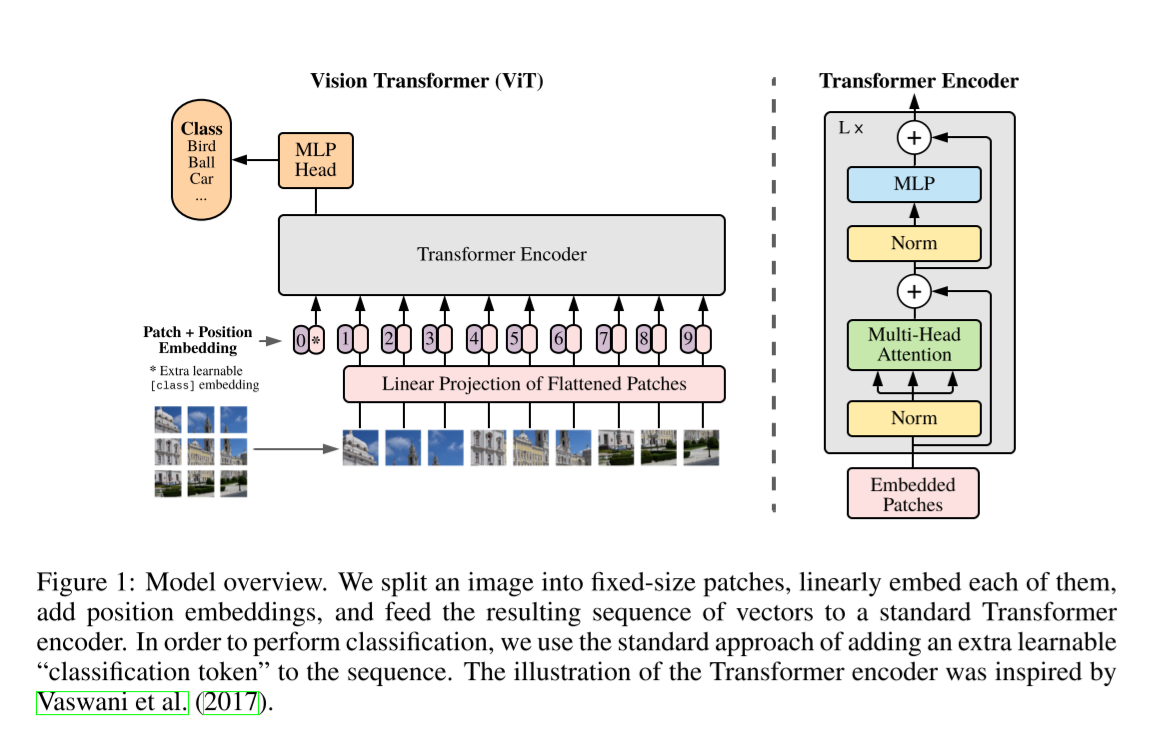
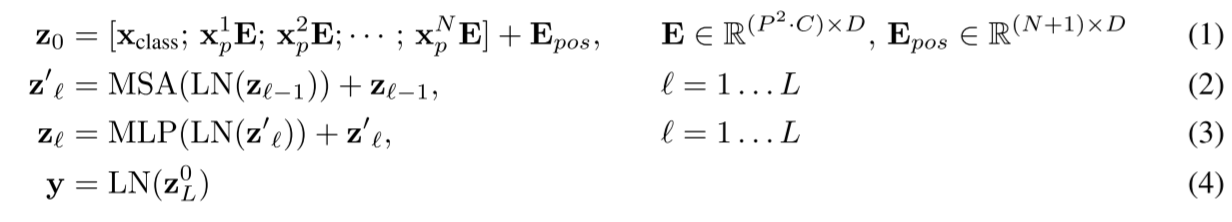
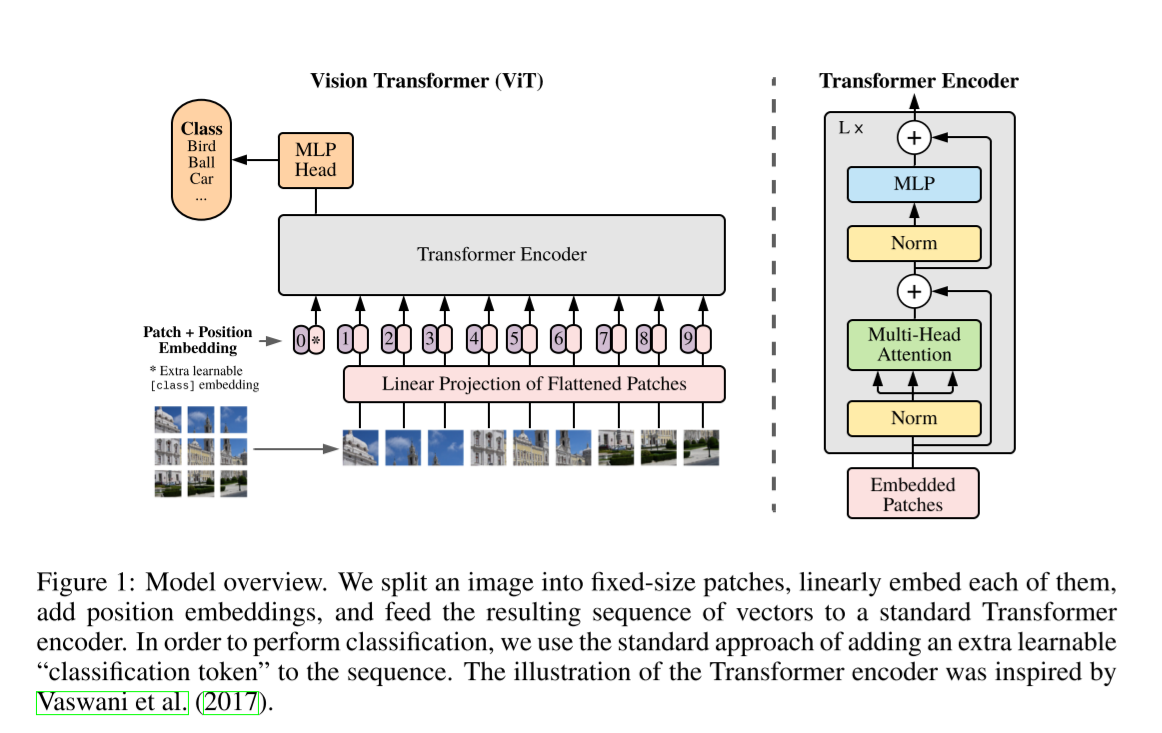
하나의 이미지를 여러 개의 Patches로 나눈 후 flatten, linear projection을 적용한다. 이후 positional encoding을 더해 Transformer Encoder에 넣고, MLP Head에서 classify를 한다.
위 그림 0번째에 [class] token이 존재하는데, 이는 transformer의 구조를 어기지 않고 classify를 하기 위한 설계라고 한다. 그런데 Appendix D.3를 보면 class token 없이도, image-patching embedding에 global average pooling(GAP) 연산을 적용하고도 learning rate만 잘 설정하면 성능이 잘 나온다. (Figure 9) 아마 Gradient Descent에 있어 dimension의 문제가 아니었나 싶다.
In order to stay as close as possible to the original Transformer model, we made use of an additional [class] token, which is taken as image representation. The output of this token is then transformed into a class prediction via a small multi-layer perceptron (MLP) with tanh as non-linearity in the single hidden layer.
중요하게 눈여겨볼 점이 몇 있다.
-
Inductive bias
CNN에서 convolution은 2차원 인접구조에 대한 locality 파악을 내재한 연산이고, translation equivariance 또한 전체 모델에 녹아있다. 그에 비해 self-attention layer은 global하고 2차원 인접구조에 대한 정보는 처음에 patching 후 positional encoding을 함으로써 유일하게 쓰인다.
논문 내용 외적으로 설명을 덧붙이자면,
inductive bias란 만나지 못한 상황을 해결하기 위해 추가적인 가정을 활용해 문제를 푸는 것을 말한다.
CNN은 locality를 활용하여 spatial problem을 풀고, RNN은 sequentiality를 활용하여 sequential problem을 푼다.
transformer에는 이러한 inductive bias가 내재되어 있지 않으므로 patching 후 positional encoding을 통해 포함시켜 주어야 한다.
-
Hybrid Architecture
raw image patches대신 CNN의 feature map이 input으로 들어올 수도 있다.
3.2 Fine-Tuning and Higher Resolution
대규모 데이터셋에 대해 pre-train 후 high resolution의 또 다른 데이터셋에 대해 transfer learning을 진행한다. (fine-tuning) 특히 positional encoding은 resolution에 맞게 2D interpolation을 이용해 적용한다. 이미지의 2D 구조에 대한 inductive bias가 유일하게 적용되는 부분이 resolution adjustment와 patch extraction임에 유의한다.
4.2 Comparison to State-of-the-Art
기존의 SoTA인 BiT와 Noisy Student를 뛰어넘는 성능을 보여준다. TPUv3-core-days도 월등히 낮은 통계를 보여준다.
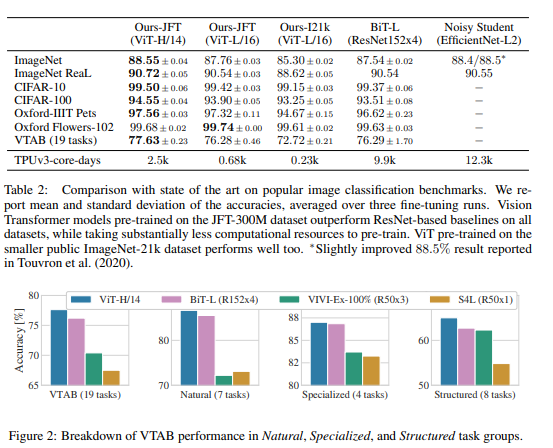
4.3 Pre-trained Data Requirements
pre-train에 사용한 데이터셋이 작을수록 성능은 급격히 떨어진다. JFT-300M 정도로 대용량의 데이터셋을 사용해야 BiT를 뛰어넘는 성능을 보인다.
또한 few-shot을 이용할 때도, pre-training image samples가 많아질수록 성능이 올라가 BiT보다 좋았다.
4.4 Scaling Study
Hybrid 모델(입력이 CNN의 결과)의 경우 pre-train에 사용한 연산량이 적을 때는 ViT보다 약간 낫지만 연산량이 커질수록 차이가 거의 없어진다.
4.5 Inspecting Vision Transformers
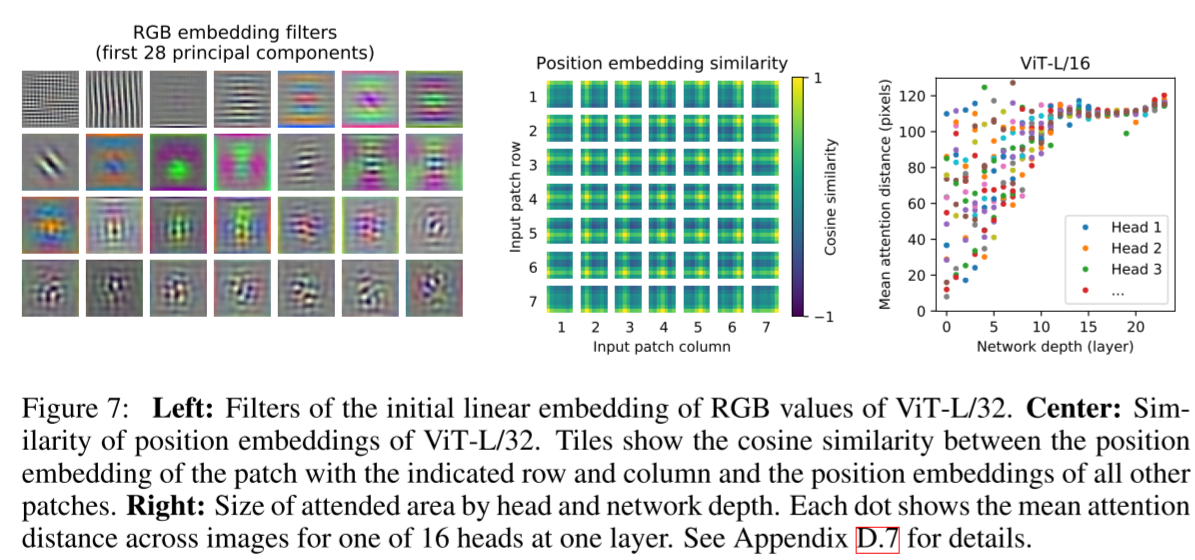
초반부 linear embedding에 사용된 필터, similarity of positional encoding, depth에 따른 Mean attention distance을 나타내는 Figure이다.
셋 모두 중요한데, 특히 오른쪽 Figure을 보자. Attention distance는 CNN에서 receptive field와 비슷한 역할을 하는 지표이다. 즉, receptive field가 깊이가 얕을 때는 작은 것도 있고 큰 것도 있다가 깊어질수록 큰 것만 남게 된다고 이해하면 된다.

Attention Rollout을 이용하면 output token에 input pixels가 얼마나 기여하는지 계산할 수 있으며, 이를 이용해 나타낸 그림이 Figure.6이다.
4.6 Self-supervision
Transformer의 NLP에서 훌륭한 성능은 excellent scalability뿐만 아니라 large scale self-supervised pre-training에서 나온다.
우리도 masked patch prediction을 시행해봤고, training from scratch보다는 2%의 상당한 향상을 이뤘지만 supervised pre-training보다는 4% 뒤쳐졌다. Appendix B1.2에 더 자세한 디테일이 있다.
self-supervised learning으로도 정확도가 오르긴 올랐지만 supervised pre-training보다는 낮아서, 아쉬운 부분이다.
5. Conclusion
pre-training on large datasets을 했을 때 ViT가 좋은 성능을 내는 것을 확인할 수 있었다.
하지만 challenge가 남아 있다. image recognotion뿐만 아니라 detection과 segmentation에도 적용할 수 있도록 하는 것, 그리고 self-supervised pre-training method를 활용할 수 있도록 하는 것이 그것이다. 이 실험에서 self-supervised pre-training에서의 향상을 보여주긴 하나 large-scale supervised pre-training과는 큰 차이가 있다. 마지막으로 ViT에 대한 추가적인 스케일링은 더욱 큰 성능 향상을 이끌 것이다.
Appendix
D.3
CLASS TOKEN을 사용하든 image-patch embeddings에 대한 GAP(global average pooling)을 사용하든 learning rate 잘 맞추면 차이는 없어진다.
D.4
여러 종류 positional embedding을 사용해봤으나, 큰 차이는 없다. positional embedding을 사용하지 않을 때는 정확도가 낮았다.
각 패치는 충분히 작고, 이 정도 크기에서 spatial relation을 배우는 건 어렵지 않아 그런 것으로 보인다고 한다.
D.8 Attention Maps
한번 읽어보자.
참고 자료
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale