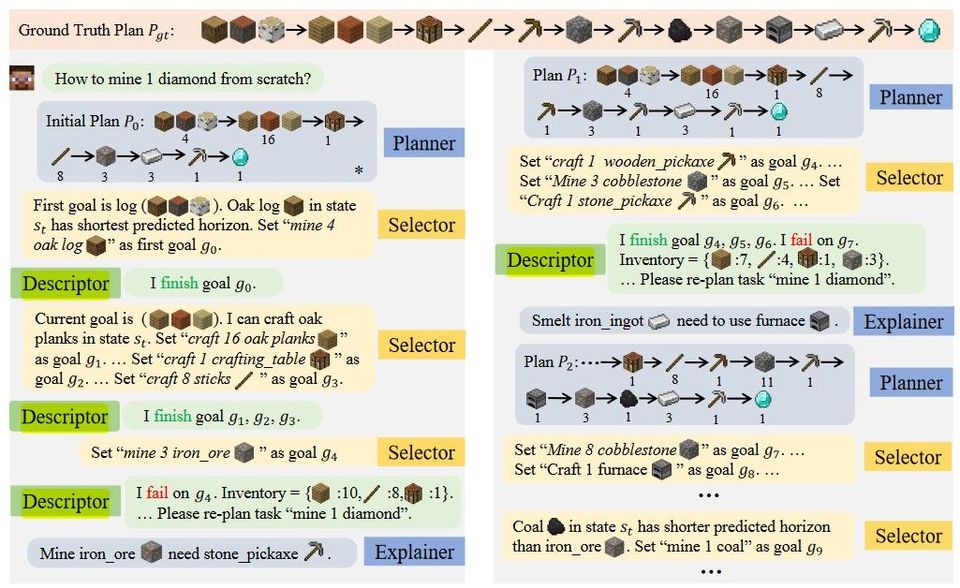
Papers Reading Describe, Explain, Plan and Select - Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents 이 글에서는 Large Language Model(LLM)에 별도의 fine-tuning을 하지 않고도 LLM을
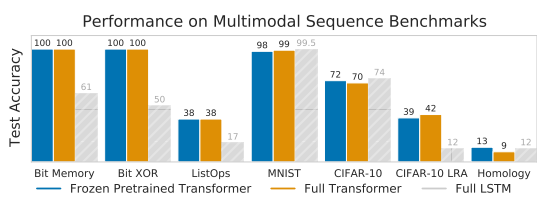
Papers Reading Pretrained Transformers as Universal Computation Engines 2021 3월 9일에 나온 Pretrained Transformers as Universal Computation Engines에 대한 간략한
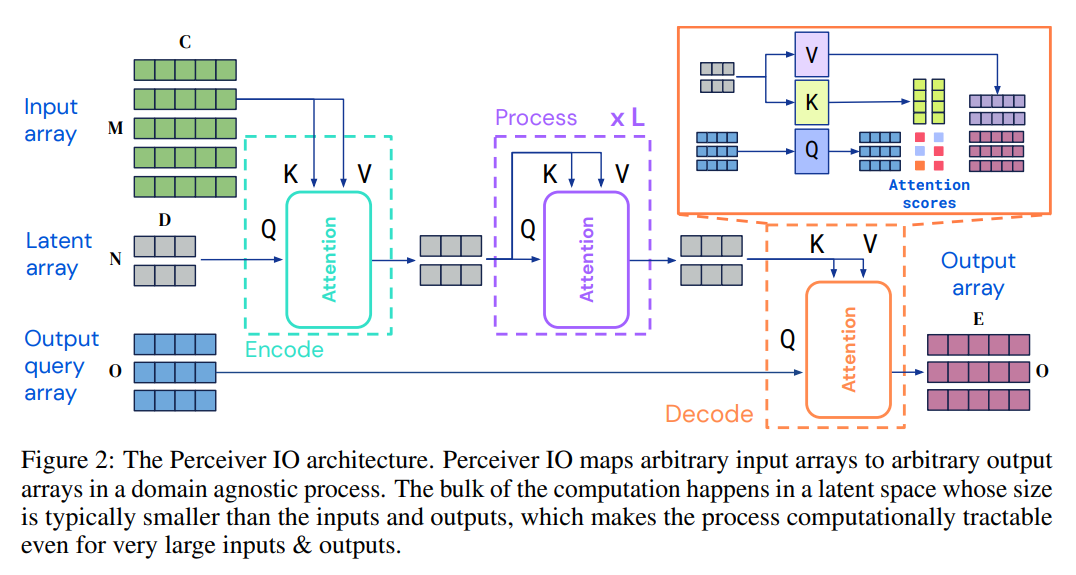
Papers Reading Perceiver IO: A General Architecture for Structured Inputs & Outputs 내가 이전에 올린 Perceiver [https://milkclouds.work/perceiver-general-perception-with-iterative-attention/] 에 대한 게시물을 참고하자.
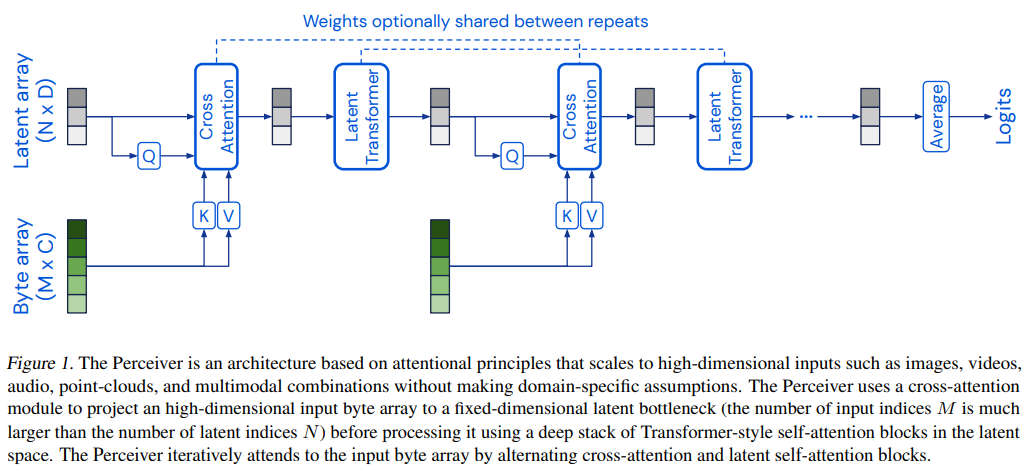
Papers Reading Perceiver: General Perception with Iterative Attention Abstract 생물학적 시스템에서는 시각, 청각, 촉각, 자기수용감각 등 다양한 양상의 고차원 입력을
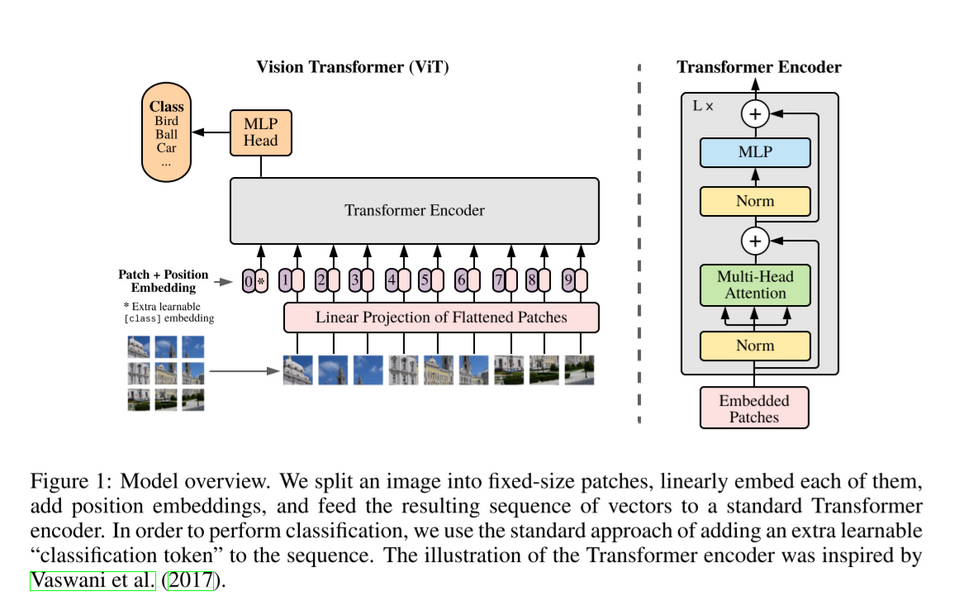
Papers Reading AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 요약 하나의 단어를 $W$개의 스칼라를 가진 벡터로 나타낼 때, 하나의 문장은
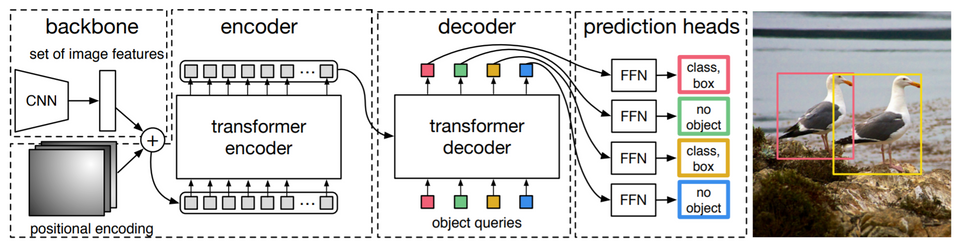
Papers Reading DETR: End-to-End Object Detection with Transformers(ECCV 2020) 요약 정해진 개수의 bounding box를 구하고, bipartite matching을 통해 ground truth box와
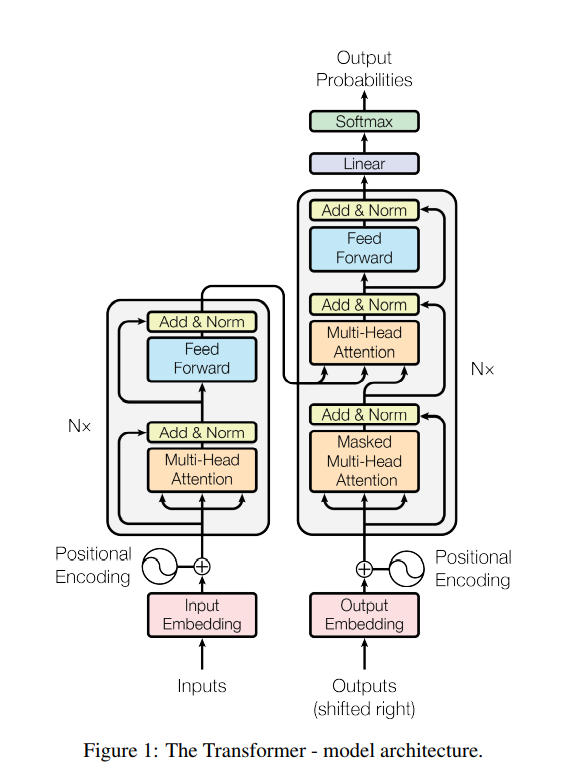
Papers Reading Attention Is All You Need(NIPS 2017) Google Research의 논문이다. 요약 무려 3만회나 인용된, 가히 혁신적이라고 할 수 있는
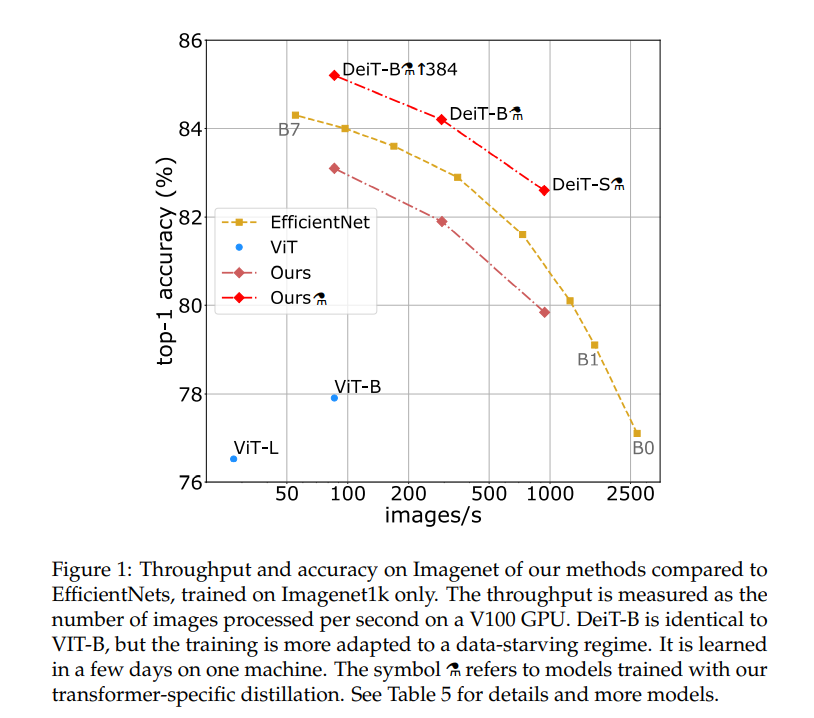
Papers Reading Training data-efficient image transformers & distillation through attention Training data-efficient image transformers & distillation through attention Recently, neural networks purely